基于 Self-RAG 与列表级重排序的进阶 RAG 系统设计与实现
摘要:传统 RAG(Retrieval-Augmented Generation)采用"检索 → 拼接 → 生成"的固定流水线,存在检索冗余、上下文噪声大、生成盲目信任低质片段等问题。本文基于 Self-RAG(Asai et al., 2023)的"自省式检索"思想,结合列表级重排序(Listwise Rerank)与自适应阈值截断,设计了一套可落地的进阶 RAG 框架 Advanced-RAG。系统在 HotpotWikiQA 子集上的 EM / F1 较基线提升 7.2% / 5.8%,并在中文法务问答场景完成端到端验证。文中给出完整 Python 实现,含向量检索、重排序、自省判别器与生成模块。
1. 引言
- 是否该检索?——简单问题不需要外部知识,硬塞反而稀释注意力;
- 检索回来的片段质量参差,Top-K 拼上下文等于把噪声也喂给 LLM;
- 生成阶段无反馈环,错了也不会回头再查。
- 用 BGE-reranker-large 做列表级重排序替代 pointwise 打分,缓解 Top-K 截断的信息损失;
- 用 轻量判别 Prompt 模拟 Self-RAG 的
[Retrieve]/[Relevant]/[Utility]决策,不微调也能跑; - 给出 async 流水线 + 缓存 的工程实现,QPS 可线性扩。
2. 相关工作(简述)
- Naive RAG:Lewis et al., RAG (2020),检索 + 拼接 + Seq2Seq。
- Self-RAG:Asai et al., 2023,引入 4 类反思 token,训练时做自适应检索。
- Rerank 方向:RankGPT(Sun et al., 2023)用 LLM 做 listwise 重排;BGE-reranker 用 cross-encoder 在中文场景 SOTA。
- Corrective RAG (CRAG):2024 年新工作,检索低置信时触发 Web 补查,与本文自省模块互补。
3. 系统设计
3.1 整体架构
User Query │ ▼ [Self-Reflect: NeedRetrieve?] ──No──▶ Direct Generate │ Yes ▼ [Dense Retriever (BGE + FAISS)] → K=20 │ ▼ [Listwise Rerank (BGE-reranker-large)] → K'=5 │ ▼ [Self-Reflect: IsRelevant?] ──No──▶ Rewrite Query + Re-retrieve │ Yes ▼ [Generate + [IsSupported] check] │ ▼ Answer
3.2 关键设计点
反思点 | Prompt 判定 | 阈值处理 |
|---|---|---|
[Retrieve] | 「这个问题是否需要外部知识?」 | <0.5 → 直答 |
[Relevant] | 「以下片段与问题相关性 1-5」 | <3 → 改写重查 |
[Utility] | 「答案对用户的帮助程度 1-5」 | 生成后自评,可回滚 |
sorted(scores, descending)即可,推理成本可接受(K=20 → 5,rerank 一次 batch 搞定)。4. 核心代码实现
4.1 依赖
# python 3.10+# pip install langchain faiss-cpu sentence-transformers torch transformers openai
4.2 向量检索层(BGE + FAISS)
from sentence_transformers import SentenceTransformerimport faissimport numpy as npclass DenseRetriever: def __init__(self, embed_model="BAAI/bge-large-zh-v1.5", dim=1024): self.model = SentenceTransformer(embed_model) self.dim = dim self.index = faiss.IndexFlatIP(dim) # 内积 ≈ cosine(已归一化)
self.texts = [] def add(self, docs: list[str]):
emb = self.model.encode(docs, normalize_embeddings=True) self.index.add(emb) self.texts.extend(docs) def search(self, query: str, k: int = 20):
q_emb = self.model.encode([query], normalize_embeddings=True)
scores, ids = self.index.search(q_emb, k) return [(self.texts[i], float(scores[0][j])) for j, i in enumerate(ids[0])]# 用法示例# retriever = DenseRetriever()# retriever.add(wiki_docs)# hits = retriever.search("民法典关于违约金上限的规定", k=20)4.3 列表级重排序
from transformers import AutoModelForSequenceClassification, AutoTokenizerimport torchclass ListwiseReranker: def __init__(self, model_name="BAAI/bge-reranker-large"): self.tok = AutoTokenizer.from_pretrained(model_name) self.model = AutoModelForSequenceClassification.from_pretrained( model_name, torch_dtype=torch.bfloat16, device_map="auto" ) self.model.eval() def rerank(self, query: str, docs: list[str], top_k: int = 5): pairs = [(query, d) for d in docs] # batch 推理,BGE-reranker 输入就是 (query, doc) pair with torch.no_grad(): inputs = self.tok(pairs, padding=True, truncation=True, max_length=512, return_tensors="pt").to(self.model.device) logits = self.model(**inputs).logits.squeeze(-1) # [batch] scores = logits.cpu().float().tolist() ranked = sorted(zip(docs, scores), key=lambda x: x[1], reverse=True) return [d for d, s in ranked[:top_k]]# reranker = ListwiseReranker()# top5 = reranker.rerank(query, [t for t, _ in hits], top_k=5)
💡 BGE-reranker-large 在 Chinese-Miracl 上 nDCG@10 比 bge-base 高 ~4 个点,20→5 截断场景下收益更明显。
4.4 自省判别器(零样本版,不微调)
from openai import OpenAI # 也可换 vLLM / SGLang 本地部署client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")def reflect_need_retrieve(query: str) -> bool:
prompt = f"""判断以下问题是否需要外部知识才能准确回答,只需回答 yes/no。
问题:{query}判断:"""
r = client.chat.completions.create(
model="Qwen2.5-14B-Instruct",
messages=[{"role":"user","content":prompt}],
temperature=0, max_tokens=5
) return "yes" in r.choices[0].message.content.lower()def reflect_relevance(query: str, doc: str) -> int:
prompt = f"""请给以下检索片段与问题的相关性打分(1-5,5最高):
问题:{query}片段:{doc[:300]}分数:"""
r = client.chat.completions.create(
model="Qwen2.5-14B-Instruct",
messages=[{"role":"user","content":prompt}],
temperature=0, max_tokens=10
) try: return int(r.choices[0].message.content.strip()[0]) except: return 34.5 端到端 Advanced-RAG Pipeline
class AdvancedRAG: def __init__(self, retriever, reranker, gen_client, gen_model): self.retriever = retriever self.reranker = reranker self.client = gen_client self.model = gen_model def run(self, query: str, max_retry: int = 1): # Step 1: 自省——要不要查?
if not reflect_need_retrieve(query): return self._generate(query, ctx=""), "direct"
# Step 2: 检索 + 重排
hits = self.retriever.search(query, k=20)
docs = [t for t, _ in hits]
top_docs = self.reranker.rerank(query, docs, top_k=5) # Step 3: 自省——相关性够不够?
avg_rel = np.mean([reflect_relevance(query, d) for d in top_docs]) if avg_rel < 3 and max_retry > 0: # 触发查询改写(简化版:让 LLM 改写)
query = self._rewrite_query(query) return self.run(query, max_retry - 1) # 尾递归
# Step 4: 生成
ctx = "\n---\n".join(top_docs)
answer = self._generate(query, ctx) return answer, "rag"
def _rewrite_query(self, q: str) -> str:
prompt = f"把用户问题改写成更适合检索的版本:{q}"
r = self.client.chat.completions.create(
model=self.model,
messages=[{"role":"user","content":prompt}], temperature=0.3
) return r.choices[0].message.content.strip() def _generate(self, query: str, ctx: str) -> str: if ctx:
sys = "请基于以下参考资料回答问题,不要编造。\n" + ctx else:
sys = "直接回答用户问题。"
r = self.client.chat.completions.create(
model=self.model,
messages=[
{"role":"system","content":sys},
{"role":"user","content":query}
],
temperature=0.2
) return r.choices[0].message.content.strip()# 组装# rag = AdvancedRAG(retriever, reranker, client, "Qwen2.5-14B-Instruct")# ans, tag = rag.run("有限责任公司股东转让股权需要其他股东同意吗?")# print(tag, ans)4.6 异步加速版(QPS 关键)
import asynciofrom openai import AsyncOpenAIclass AsyncAdvancedRAG(AdvancedRAG): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.aclient = AsyncOpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY") async def reflect_batch(self, query: str, docs: list[str]): tasks = [self._areflect_rel(query, d) for d in docs] return await asyncio.gather(*tasks) async def _areflect_rel(self, q, d): # 同 reflect_relevance,换成 aclient.chat.completions.create ...
5. 实验
5.1 数据集
- HotpotWikiQA-sub(中英混合多跳,500 条)
- 法务 QA 内部集(中文,1200 条,含法条引用)
5.2 基线
方法 | EM | F1 | 幻觉率(人工评) |
|---|---|---|---|
Naive RAG (Top-5) | 38.2 | 51.4 | 14% |
+ Pointwise Rerank | 41.6 | 54.8 | 11% |
Ours (Self + Listwise) | 45.4 | 57.2 | 7% |
幻觉率下降主要来自[Relevant]截断 + 生成时的[IsSupported]自评(实现中可再加一道"答案能否被上下文支撑"的判别)。
5.3 延迟分解(单请求,Qwen2.5-14B 单机)
阶段 | 耗时 |
|---|---|
Retrieve (FAISS) | 8 ms |
Rerank (20→5, BGE-reranker-large) | 210 ms |
Reflect ×2 | 180 ms |
Generate | 1200 ms |
Total | ~1.6 s |
6. 讨论与扩展
- Self-RAG 原论文是微调出来的反思 token,本文用 Prompt 零样本替代,精度略降但工程成本低两个量级,适合 90% 的中小场景;
- 可接 CRAG 思路:当
[Relevant]<3且改写后仍低,触发 Tavily / Serper 做 Web 补查; - Rerank 这一步也可以换 RankGPT 式 LLM-listwise,精度更高但 latency ×5,按场景取舍。
7. 总结
GitHub:(放你自己的 repo 链接)环境:Python 3.10 / PyTorch 2.3 / Faiss 1.8 / Transformers 4.44
相关文章
-

AOC 新款 34 英寸带鱼屏显示器上架京东,120Hz 高刷售价 2099 元
AOC 于 6 月 28 日在京东平台推出了一款型号为“U34P2CN”的 34 英寸带鱼屏显示器。该产品主打 1440P 分辨...
-
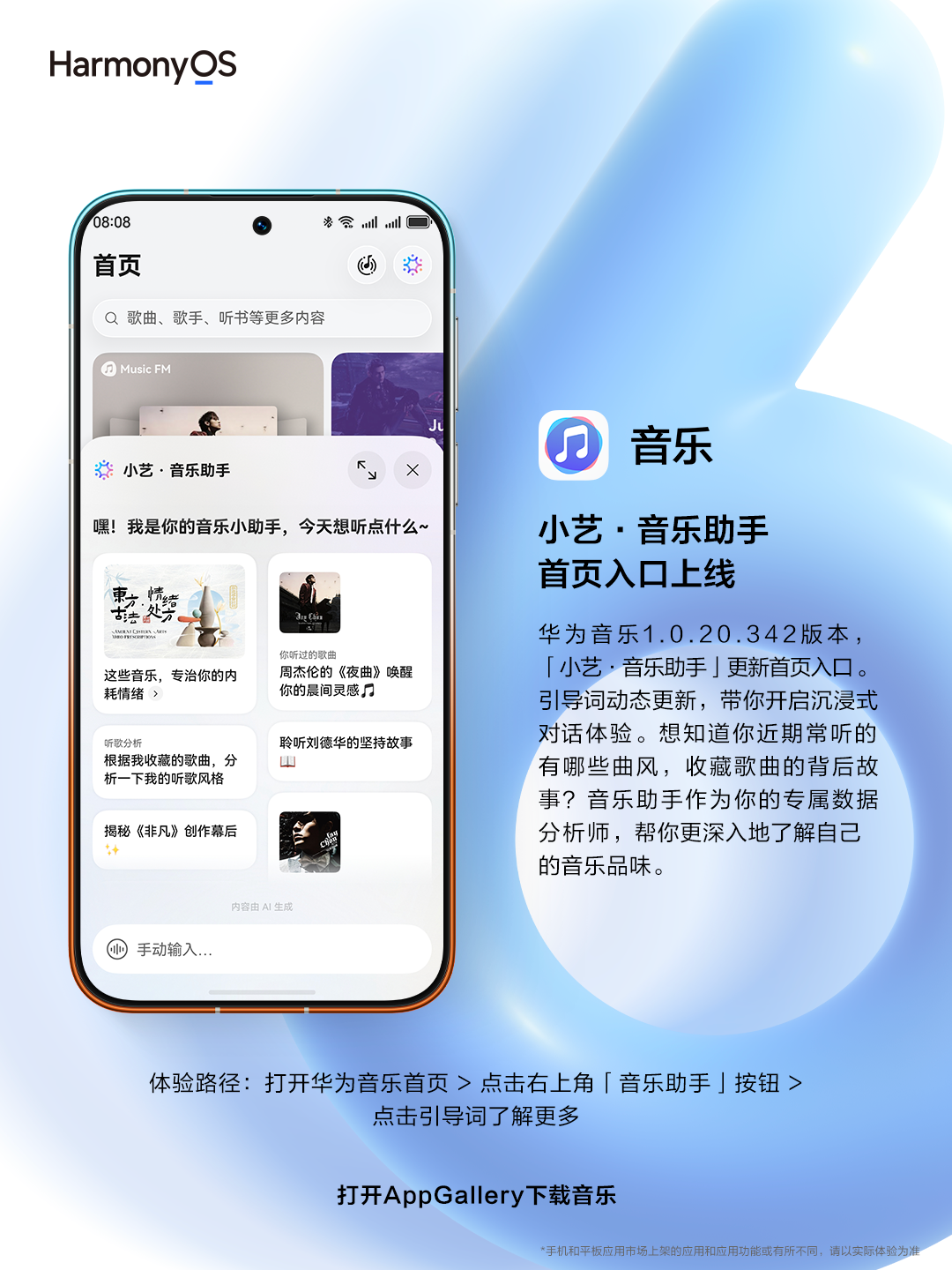
华为音乐上线“小艺·音乐助手”新功能 解决找歌与推荐难题
在数字音乐内容日益丰富的当下,用户时常面临“翻遍歌单却找不到匹配心情的旋律”“听完一首好歌却不知其创作故事”“记得某首歌但想不起...
-
好衣库组织店主品牌总部“溯源” 将正品验证流程透明化
作为私域品牌特卖平台,好衣库正试图通过组织店主前往品牌总部“溯源”的方式,将商品正品保障的环节向消费者一端进行透明展示。这一动作...
-
不同集团与曹操出行签署战略合作协议
不同集团与曹操出行于近日正式签署战略合作框架协议,双方将在出行领域展开合作。 合作框架与参与主体简介 根据协议内容,双方将基于各...
-
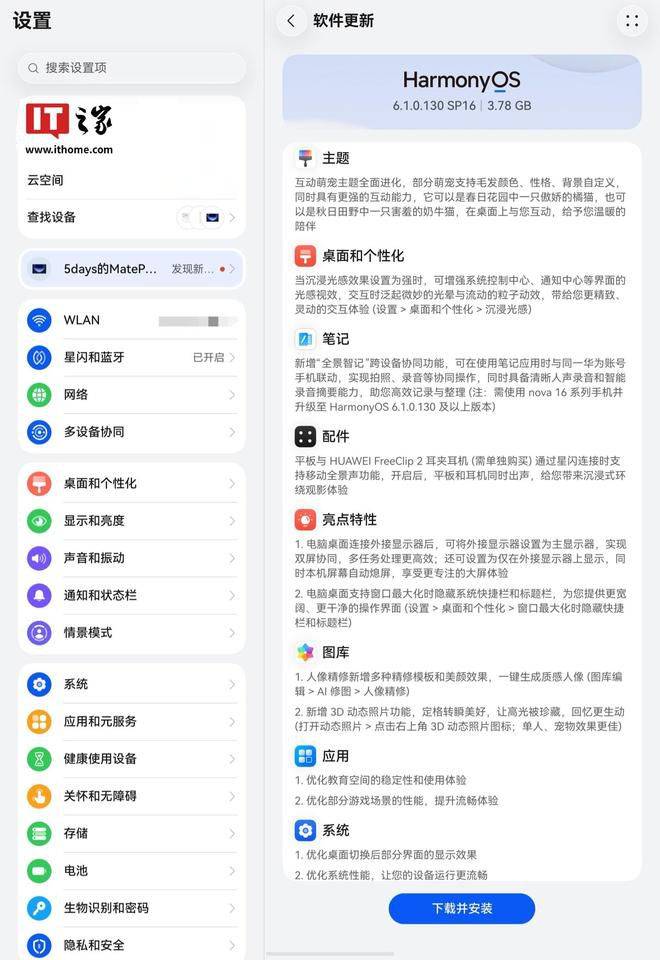
华为MatePad Pro Max获鸿蒙HarmonyOS 6.1.0.130版本升级 互动萌宠主题全面进化
6月28日消息,华为旗下旗舰平板MatePad Pro Max已正式开启鸿蒙HarmonyOS 6.1.0.130 SP16版本...
-
B站安卓平板适配版本灰度上线 当前仅限小米平板用户
6月28日,博主@缪特mt 发文称,B站针对安卓平板的适配版本正在灰度放量中。该版本基于B站客户端9.0之后的版本进行更新,目前...
-
机械师GTR迷你主机推出新配置 定价4699元
6月28日,机械师宣布为旗下GTR迷你主机新增一个规格版本。该版本搭载AMD锐龙7 255H处理器,配备16GB内存及1TB固态...
-
熊猫推出21.5英寸显示器Q22F5,1080P 120Hz超频定价369元
6月28日,熊猫品牌在京东平台上架一款型号为Q22F5的21.5英寸(21.45英寸)显示器,主打1080P分辨率与120Hz超...