突破算力壁垒:HRM-Text引入MagicNorm技术推动企业级紧凑推理模型落地
0
算力门槛显著降低:HRM-Text训练框架问世 十亿参数基础模型成本压至千美元级
近日,人工智能基础模型研发领域取得一项关键技术突破。由独立研究团队开发的HRM-Text语言模型训练方案成功实现十亿参数基础模型的低成本从零预训练。该方案在仅调用16块图形处理器、耗时不足两天、综合计算成本控制在1500美元左右的条件下完成模型构建,为打破当前大模型产业对超高算力与海量语料的依赖提供了全新的技术路径。
长期以来,基础人工智能大模型的训练生态逐渐向算力密集型模式演进,传统范式往往需要部署数千张高端加速卡,消耗数百万美元级资金,并处理数以PB计的高质量互联网文本。此次公布的HRM-Text方案则展示了差异化的技术逻辑。研究人员通过优化数据采样策略与训练算法架构,在严格控制硬件资源配额的前提下,将十亿参数规模语言模型的收敛周期压缩至1.9天。硬件投入方面,仅通过16个标准计算单元即可完成全流程预训练,整体算力开销被大幅压缩至千美元量级。
该技术方案的核心价值在于重构了模型预训练阶段的资源分配逻辑。研究团队指出,以往的性能提升通常与参数规模、数据体量进行强绑定,导致技术研发门槛不断抬高。HRM-Text通过算法层面的精细化调度与数据效率优化,有效削弱了基础模型对极端计算资源的刚性需求。这一突破不仅有助于缩短底层模型迭代周期,更为学术界与科技企业参与大模型研发提供了可操作的实践范本,推动人工智能底层技术向更加高效、普惠的方向演进。
业内分析认为,随着基础模型训练成本曲线的下移,人工智能技术的研发重心或将逐步从单纯的规模扩张转向算法创新与场景适配。尽管目前该方案仍处于技术验证阶段,其最终部署效能及跨场景泛化能力仍需经过更广泛基准测试的检验,但其展现出的技术可行性已引发行业广泛关注。未来,若类似低成本训练框架能够进一步与垂直领域知识库结合,有望加速智能技术在更多细分产业中的落地应用,重塑当前基础模型的开发与普及格局。

突破传统架构瓶颈:HRM-Text大模型以任务导向重塑AI推理路径* 近期,人工智能基础模型领域迎来一项重要架构革新。由相关研究团队自主研发的HRM-Text模型正式公开技术细节,该模型彻底摒弃业界主流的分形变压器(Transformer)路线,创新采用分层循环架构,并将训练重心从传统的文本续写转向任务完成度优化。这一技术路线的转换,标志着生成式人工智能正加速向垂直场景与效能交付迈进。
据CNMO科技获取的技术资料披露,HRM-Text在底层算力分配与逻辑推演机制上实现了底层重构。不同于依赖自注意力机制处理长序列的传统大语言模型,该模型引入了分层循环网络(HRM)作为核心底座。其计算框架被科学解耦为策略层与执行层:策略层负责宏观逻辑规划与状态维持,具有相对稳定的参数迭代周期;执行层则专注于微观动作生成与快速响应,承担高频次的数据流转任务。这种动静分离的设计,有效降低了冗余计算开销,提升了模型在复杂链路中的稳定性。
在训练范式层面,HRM-Text打破了依赖海量无监督语料进行“下一个词预测”的传统路径。研究团队明确指出,该模型的训练数据集完全由高质量的“指令-回复”配对数据构成。算法的优化目标随之发生根本性转移,系统不再以字粒度的文本连贯性为评判标准,而是直接锚定任务完成度与最终输出质量。通过强化学习等机制对结果导向进行梯度更新,模型能够在有限的算力资源下,快速收敛至符合业务逻辑的解答路径,显著减少了无效参数的训练损耗。
这一技术路线的演变,深刻契合了当前产业智能化转型的实际需求。研究团队在技术说明中指出,企业在部署人工智能系统时,核心诉求往往并非文本创作的多样性,而是针对具体业务问题的精准解答与高效执行。HRM-Text以任务完成为导向的设计哲学,使其在客户服务、自动化办公、数据分析等垂直领域展现出更强的落地适应性。随着大模型技术从“通用能力堆叠”向“精准效能交付”转型,此类注重架构精简与目标导向的模型架构,有望为企业级AI应用提供更具性价比的底层支撑。
大模型训练新范式:HRM-Text以精细化语料策略重塑层级推理机制* 近日,人工智能基础模型研发领域公布了一项关于训练架构优化的关键技术进展。名为HRM-Text的大语言模型在语料构建与推理机制设计上采用差异化技术路径,通过约400亿token的精选数据规模与定向训练干预策略,成功激活高效的内部层级推理网络,为当前业界普遍采用的规模扩张路线提供了具有参考价值的算法实证。
在训练语料规模的战略选择上,该模型并未跟随主流技术路线追求万亿级token数据的粗放式堆叠,而是将总数据量严格控制在400亿token左右。这一技术取舍旨在提升数据处理的边际效益与模型学习效率。据研发团队披露,HRM-Text所采用的核心语料库由高质量“指令-回复”配对样本构成,内容维度全面覆盖通用指令应答、高等数学演算、符号逻辑推演、标准化教材习题以及结构化知识改写等垂直领域。研究团队通过多层级清洗与质量过滤机制,有效剔除了低效噪声数据,确保模型在相对紧凑的数据规模内完成核心认知能力的构建。
针对模型逻辑推演路径的底层优化,技术团队在训练阶段实施了一项关键的架构干预:系统性地剥离训练数据中显式展示中间推理步骤的标记序列。该操作的核心技术目的在于切断模型对显式步骤输出的参数依赖,转而引导其激活并强化内部多层级的隐式推理网络。从深度学习算法机制来看,这种“去显式化”的训练干预迫使模型在参数空间内自行构建复杂的逻辑映射与知识关联,从而显著提升其信息整合效率与跨域泛化表现。实验数据表明,该机制能够有效抑制训练过程中的冗余计算开销,使模型在维持高逻辑严密性的同时,实现算力资源利用率的结构性优化。
当前人工智能领域关于模型扩展定律与训练效率的学术探讨日趋深入,HRM-Text的技术路径为“数据质量”与“算法架构”的协同演进提供了重要参考。通过在语料构成上实施垂直化深耕,并在训练干预环节聚焦于隐式逻辑结构的激活,该技术路线在一定程度上突破了传统依赖海量数据堆砌的增长瓶颈。业内分析指出,此类精细化训练范式不仅有助于降低大规模模型的算力部署门槛,也为后续在金融、医疗、教育等垂直行业场景中的高效落地奠定了算法基础。随着机器学习架构的持续迭代,基于层级推理与高质量语料耦合的技术方向,有望在下一代人工智能系统的研发进程中发挥更为关键的基础性作用。
十亿参数大模型实现效能突破 资源消耗大幅降低对标主流开源架构* 近日,人工智能基础研发领域迎来一项轻量化模型训练技术的关键进展。最新测试数据表明,一款仅含十亿(10亿)参数规模的深度学习模型,在多项权威基础能力评估中展现出与主流大规模开源模型相匹敌的综合性能。该技术路径在大幅削减训练数据用量与算力开销方面取得显著成效,为行业探索高效、低碳的人工智能研发模式提供了新范式。
评估数据显示,该模型在自然语言理解与逻辑推理等核心维度的测试中表现稳健。具体而言,其在综合性知识基准测试MMLU中取得60.7%的正确率,在数学推理基准GSM8K中得分达到84.5%,在高等数学与复杂逻辑推理基准MATH中亦录得56.2%的成绩。多项基准测试的优异表现证明,通过算法优化与训练策略迭代,参数规模的缩减并未对模型的核心认知能力造成实质性削弱,其在复杂任务处理上已具备与更大规模开源模型直接竞争的技术潜力。
在模型研发的资源投入维度,该技术路线展现出显著的效率优势。据研发团队披露,该十亿参数模型在预训练阶段所消耗的数据标记数量,相较于部分知名大型开源模型(如Qwen、Gemma及Llama系列的部分版本),减少了100倍至900倍不等。同步测算表明,整体训练过程中的计算资源消耗亦降低96倍至432倍。这一量级的资源优化,有效打破了传统大模型研发对海量数据与超算集群的高度依赖,大幅压降了技术迭代的经济成本与能源门槛。
当前,全球人工智能产业正逐步从追求参数规模扩张转向追求单位算力效能提升。该模型的成功研发,不仅验证了轻量化架构在保持高泛化能力方面的可行性,也为算力资源受限的研发机构及企业提供了更具性价比的技术方案。随着高效训练框架的持续演进,此类低资源消耗、高输出表现的模型架构有望在垂直行业落地、边缘计算设备及定制化智能服务中发挥更广泛的产业价值,进一步推动人工智能技术向规模化、普惠化方向迈进。
本报讯 近日,人工智能基础模型研究团队在训练架构优化方面取得阶段性技术进展。针对循环语言架构训练过程中频发的梯度异常波动问题,研发团队成功部署MagicNorm归一化算法,并配套实施推理深度渐进式预热方案。该路径的验证有效拓宽了大模型预训练的技术边界,标志着算力资源密集型研发模式正逐步向数据驱动型轻量化架构转型,为企业自主构建紧凑型推理引擎提供了可落地的技术范式。
在深度学习模型的反向传播过程中,循环结构往往伴随梯度的指数级放大或迅速衰减,该现象不仅延缓模型收敛速度,亦会削弱底层语义表征的稳定性。为破解这一技术瓶颈,研究方案引入MagicNorm归一化机制,通过动态校准特征空间分布,有效平滑了优化轨迹上的梯度震荡。与此同时,训练流程摒弃了传统的单阶跃式参数更新模式,转而采用推理深度逐级递增的预热策略。该机制使模型在受控环境下按认知规律逐步加载复杂逻辑任务,显著增强了网络结构的鲁棒性与跨域泛化能力。
技术验证的顺利推进,为行业重新评估模型研发门槛提供了新视角。长期以来,基础大模型的预训练高度依赖头部机构掌握的顶级算力集群与超大规模语料库,呈现出显著的资源集中特征。本次技术突破表明,借助精细化的梯度调控手段与结构化训练策略,企业完全能够依托自身沉淀的业务数据资产与外部专业知识库,定向迭代更为紧凑的推理核心模型。这一技术转向有望降低底层架构部署门槛,推动人工智能能力向制造业、金融、政务等垂直领域深度渗透,加速产业数字化与智能化融合进程。
研发团队对当前技术成熟度亦保持了审慎评估。据项目披露,HRM-Text系统现阶段主要定位于技术概念验证(PoC),尚未具备直接替代通用对话产品的商业化条件。在复杂业务场景下的多轮交互一致性、推理模式的精准切换控制,以及高并发环境下的工程化适配等方面,仍需开展系统性算法调优与基础设施升级。后续研究团队将聚焦长上下文记忆管理与端侧部署优化,持续推动原型架构向标准化产品形态演进。



 本报讯 近日,人工智能基础模型研究团队在训练架构优化方面取得阶段性技术进展。针对循环语言架构训练过程中频发的梯度异常波动问题,研发团队成功部署MagicNorm归一化算法,并配套实施推理深度渐进式预热方案。该路径的验证有效拓宽了大模型预训练的技术边界,标志着算力资源密集型研发模式正逐步向数据驱动型轻量化架构转型,为企业自主构建紧凑型推理引擎提供了可落地的技术范式。
在深度学习模型的反向传播过程中,循环结构往往伴随梯度的指数级放大或迅速衰减,该现象不仅延缓模型收敛速度,亦会削弱底层语义表征的稳定性。为破解这一技术瓶颈,研究方案引入MagicNorm归一化机制,通过动态校准特征空间分布,有效平滑了优化轨迹上的梯度震荡。与此同时,训练流程摒弃了传统的单阶跃式参数更新模式,转而采用推理深度逐级递增的预热策略。该机制使模型在受控环境下按认知规律逐步加载复杂逻辑任务,显著增强了网络结构的鲁棒性与跨域泛化能力。
技术验证的顺利推进,为行业重新评估模型研发门槛提供了新视角。长期以来,基础大模型的预训练高度依赖头部机构掌握的顶级算力集群与超大规模语料库,呈现出显著的资源集中特征。本次技术突破表明,借助精细化的梯度调控手段与结构化训练策略,企业完全能够依托自身沉淀的业务数据资产与外部专业知识库,定向迭代更为紧凑的推理核心模型。这一技术转向有望降低底层架构部署门槛,推动人工智能能力向制造业、金融、政务等垂直领域深度渗透,加速产业数字化与智能化融合进程。
研发团队对当前技术成熟度亦保持了审慎评估。据项目披露,HRM-Text系统现阶段主要定位于技术概念验证(PoC),尚未具备直接替代通用对话产品的商业化条件。在复杂业务场景下的多轮交互一致性、推理模式的精准切换控制,以及高并发环境下的工程化适配等方面,仍需开展系统性算法调优与基础设施升级。后续研究团队将聚焦长上下文记忆管理与端侧部署优化,持续推动原型架构向标准化产品形态演进。
本报讯 近日,人工智能基础模型研究团队在训练架构优化方面取得阶段性技术进展。针对循环语言架构训练过程中频发的梯度异常波动问题,研发团队成功部署MagicNorm归一化算法,并配套实施推理深度渐进式预热方案。该路径的验证有效拓宽了大模型预训练的技术边界,标志着算力资源密集型研发模式正逐步向数据驱动型轻量化架构转型,为企业自主构建紧凑型推理引擎提供了可落地的技术范式。
在深度学习模型的反向传播过程中,循环结构往往伴随梯度的指数级放大或迅速衰减,该现象不仅延缓模型收敛速度,亦会削弱底层语义表征的稳定性。为破解这一技术瓶颈,研究方案引入MagicNorm归一化机制,通过动态校准特征空间分布,有效平滑了优化轨迹上的梯度震荡。与此同时,训练流程摒弃了传统的单阶跃式参数更新模式,转而采用推理深度逐级递增的预热策略。该机制使模型在受控环境下按认知规律逐步加载复杂逻辑任务,显著增强了网络结构的鲁棒性与跨域泛化能力。
技术验证的顺利推进,为行业重新评估模型研发门槛提供了新视角。长期以来,基础大模型的预训练高度依赖头部机构掌握的顶级算力集群与超大规模语料库,呈现出显著的资源集中特征。本次技术突破表明,借助精细化的梯度调控手段与结构化训练策略,企业完全能够依托自身沉淀的业务数据资产与外部专业知识库,定向迭代更为紧凑的推理核心模型。这一技术转向有望降低底层架构部署门槛,推动人工智能能力向制造业、金融、政务等垂直领域深度渗透,加速产业数字化与智能化融合进程。
研发团队对当前技术成熟度亦保持了审慎评估。据项目披露,HRM-Text系统现阶段主要定位于技术概念验证(PoC),尚未具备直接替代通用对话产品的商业化条件。在复杂业务场景下的多轮交互一致性、推理模式的精准切换控制,以及高并发环境下的工程化适配等方面,仍需开展系统性算法调优与基础设施升级。后续研究团队将聚焦长上下文记忆管理与端侧部署优化,持续推动原型架构向标准化产品形态演进。 相关文章
-
小米汽车6月12日官宣德克兰·赖斯担任YU7体验官
6月12日,小米汽车官方宣布,英格兰职业足球运动员德克兰·赖斯正式成为小米YU7体验官。 关于德克兰·赖斯 德克兰·赖斯是英超联...
-
Omdia报告:2026年Q1全球LED视频显示屏出货量微增0.6%,收入同比下降2.3
财联社6月12日电,市场研究机构Omdia最新发布的《LED视频显示市场追踪报告》显示,2026年第一季度,全球LED视频显示屏...
-
CrossOver 27 发布:全面转向 ARM64,仅支持 Apple Silicon 与 macOS Sonoma
IT之家 6 月 12 日消息,科技媒体 Appleinsider 昨日(6 月 11 日)发布博文,报道称 CrossOver...
-
鸿蒙开发者节目《鸿蒙脑洞大开麦》将于HDC 2026期间直播
6月13日,中国首档科技开放麦节目《鸿蒙脑洞大开麦》将在华为开发者大会2026(HDC 2026)期间,于央视新闻与华为官方平台...
-
广汽传祺首届用户大会在杭州举办 两款PHEV MPV正式上市
6月11日,广汽传祺首届用户大会暨MPV之夜活动在杭州电竞中心举行。这场以“以更好 致最爱”为主题的聚会,吸引了来自全国的传祺车...
-
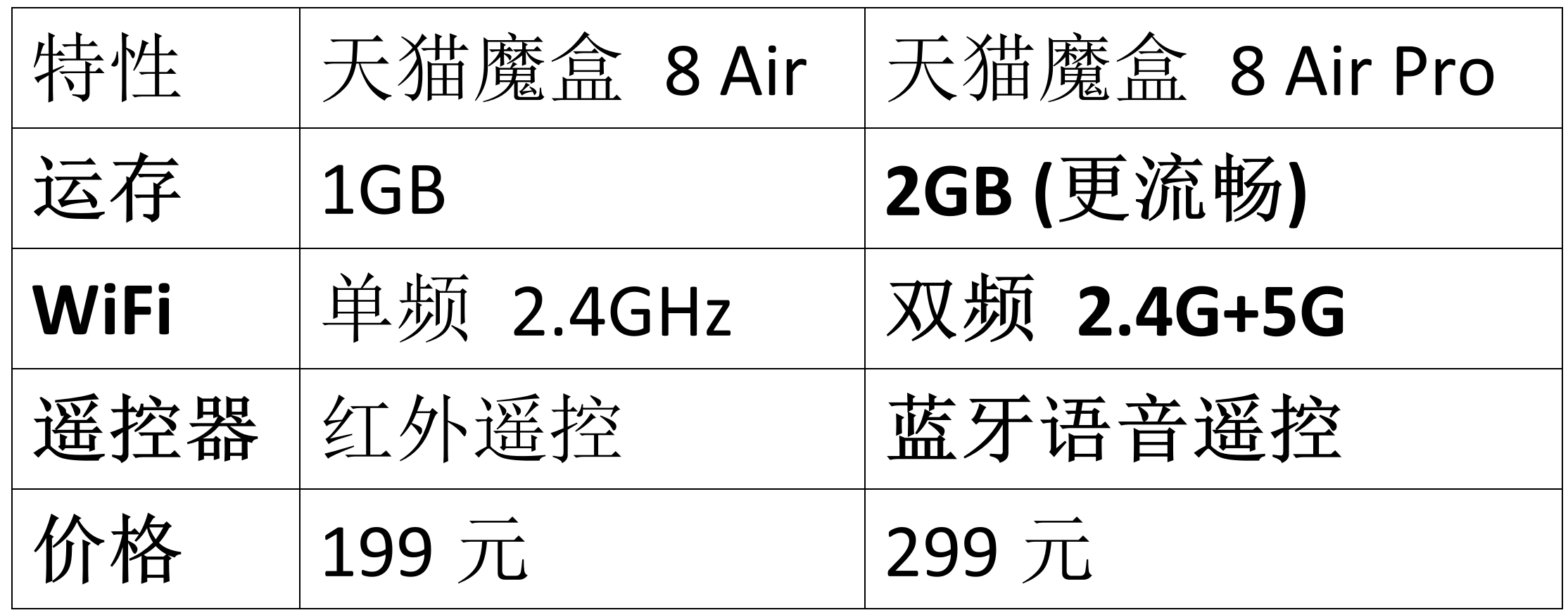
天猫魔盒8 Air/Pro发布:瞄准租房市场,以32GB存储与双频WiFi应对旧电视卡顿
针对出租屋场景中老旧电视系统卡顿、应用安装受限的普遍问题,天猫近日推出了魔盒8 Air与8 Air Pro两款电视盒子产品。官方...
-
部分Mac RAID阵列机箱被曝不兼容macOS 27 Golden Gate系统
科技媒体Appleinsider于6月11日发布博文称,部分依赖厂商专用软件的Mac RAID阵列机箱无法兼容苹果macOS 2...
-
百元价位白酒竞争逻辑生变:一担粮、汾酒等5款产品角逐“口感性价比”赛道
据中国酒业协会、尚普咨询联合发布的行业数据显示,白酒行业的竞争重心正从价格比拼转向品质工艺、饮用健康化与场景适配性。在此趋势下,...