LLW低延迟宽DRAM方案进入智能手机行业视野,设计借鉴HBM集成思路
智能手机端侧AI对算力与数据吞吐能力提出更高要求,一种名为LLW的内存技术正在成为行业讨论的新方向。
端侧AI负载驱动内存技术迭代
随着生成式AI开始向移动端部署,设备在运行模型时需要同时处理大量并行计算和海量数据搬运。现有移动内存架构在应对这种双重压力时,其延迟与带宽指标逐渐显现出瓶颈。
端侧AI对算力和数据吞吐能力的需求正在不断提升。
在此背景下,内存子系统的性能表现直接影响AI推理速度与能效比。业界开始探索能否在手机有限的空间与功耗约束内,引入更具吞吐效率的存储方案。
LLW方案技术路径分析
LLW即低延迟宽DRAM,其核心设计目标是同时降低数据访问延迟并增宽传输通道。这一思路与高带宽内存存在相似之处。
所谓高带宽内存(HBM),是通过3D堆叠将多层DRAM垂直集成,并利用密集的硅通孔和宽接口实现极高的数据传输速率。LLW正在借鉴这种集成方式,试图将部分逻辑层与存储层的耦合关系移植到移动平台上。
智能手机内部空间极为紧凑,传统内存通常采用PoP封装堆叠在应用处理器上方。这意味着LLW若要在该形态下实现宽接口与低延迟特性,需对封装层级和互连方式进行重新设计,而不是简单复制HBM架构。
PoP封装是将存储芯片直接堆叠在逻辑芯片上方的一种封装形式,能够节省主板面积并缩短信号传输路径。
业界关注焦点与技术挑战
目前这一方案仍处于行业讨论阶段。在移动端实现宽接口布局,需要在功耗控制、散热能力以及成本之间找到平衡点。如何在不过度增加机身厚度的情况下完成物理集成,也是技术推进中面临的实际约束。
从设计思路上看,LLW试图打通计算单元与内存之间的数据通路,从而缓解端侧AI任务中常见的“内存墙”问题。这一路径走向落地仍需经过验证。
该技术若能成熟应用,有望直接提升手机端大模型推理的响应速度与能耗表现。

LLW内存技术功耗降约50%性能升约1.5倍 国内手机厂商或于2027年下半年取得进展
新型低延迟宽内存(LLW)被视为智能手机突破端侧AI算力瓶颈的潜在路径之一,其理论能效与性能提升数据近期通过数码博主披露,小米与华为被提及为这一方向上的主要推动厂商。
商用时间:短期大规模落地存难,2027年下半年成关键节点
根据数码博主透露的信息,国内手机厂商在短期内对新一代内存技术实现大规模商用仍面临挑战,但相关产品有望在2027年下半年见到实质性进展。这一节奏意味着产业链需在封装、散热及成本等环节完成适配。
技术替代逻辑:HBM难以直入手机,LLW以紧密集成设计切入
高带宽内存(HBM)虽然在计算领域表现突出,但其对封装和散热的高要求使其很难直接应用于智能手机等对空间和功耗敏感的终端。LLW正是基于这一现实被提出,它并非严格意义上的HBM,而是通过更紧密的集成方案,试图突破传统LPDDR内存在带宽与延迟上的限制,从而满足未来端侧AI模型运行的需求。
LLW理论上能够在降低约50%功耗的同时,实现约1.5倍的性能提升。不过,相关数据的具体对比对象并未被明确说明,因此实际表现仍有待后续验证。
参与方角色:小米与华为被指为潜在推动者
在目前的公开线索中,小米与华为两家国内手机厂商被认为是LLW技术落地的潜在核心推动方。二者在高端机型及芯片平台上的投入,或为内存架构革新提供试验场景。
从技术角度解读,LLW所强调的“紧密集成设计”意指将内存与处理器在物理层面更深度地耦合,以缩短数据传输路径,从而降低延迟与功耗。这一思路若成功运用,意味着智能手机在进行AI推理等任务时,不必依赖远端云端算力,本地响应效率将获得提升。
尽管理论数据亮眼,由于对比基准缺失,功耗与性能的量化改善幅度还需在具体产品化后,与当前主流旗舰内存方案横向比较才能确定。产业层面,若2027年下半年如期出现商用信号,智能手机端侧AI的竞争格局或将围绕内存架构展开新一轮调整。

手机端侧AI规模持续扩大 内存带宽与延迟成行业关注节点
移动端人工智能模型体量不断增长的趋势下,依赖处理器性能单点提升的路径正遭遇瓶颈,内存系统的传输效率被业界视为影响终端体验的关键环节。
处理器升级难解渴 内存架构重要性上升
与过往侧重于神经网络处理器(NPU)算力迭代或存储介质优化不同,更高带宽、更低延迟的内存设计,开始被行业参与者视作应对端侧AI需求的一个潜在突破方向。
业内普遍认为,仅依靠提升处理器性能已难以满足需求,内存系统正成为影响体验的重要环节。相比单纯升级NPU或存储方案,更高带宽、更低延迟的内存架构被视为未来突破方向之一。
NPU作为集成于芯片中的专用加速单元,负责高效执行深度学习推理任务。而内存架构规定了计算单元存取数据的速率与时延。当AI模型参数规模扩大、实时运算频次增多时,若内存带宽不足,数据搬运易出现拥堵;延迟偏高则会拉长任务响应间隔,直接影响用户可感知的流畅度。
从组件优化到系统协同的逻辑拆解
内存架构的改进行动,实质是缩短处理器与数据存储之间的物理和逻辑通路,而非简单扩大存储容量。带宽可理解为数据通道的“车道数量”,延迟则对应指令往返一次的时间开销。两者共同决定端侧AI在语音交互、影像处理等场景下的反应速度和能效表现。
从市场层面看,这一技术共识可能推动手机厂商在下一代设备中更强调内存规格的升级,而不再仅将卖点集中于处理器核数或AI算力数字,进而引导供应链资源向内存接口、封装等环节倾斜。
相关文章
-

三星Galaxy Book 6 Edge海外正式上市 16GB+1TB版定价2100美元
三星在今年4月发布的新款Arm架构笔记本Galaxy Book 6 Edge,目前已在海外市场开启销售。该机型搭载高通Snapd...
-
三星多款新品通过FCC认证 折叠屏手机Z Fold 8 Wide未现身引关注
在新一届Galaxy Unpacked发布会即将到来之际,三星多款尚未正式推出的设备近期集中出现在美国联邦通信委员会(FCC)认...
-
华为新专利显示其探索纵向三折叠屏手机方案
一项由华为技术有限公司申请的新专利近日对外公开,文件中描述了一种可折叠电子设备的设计方向,其核心特征为纵向三折叠结构。 纵向三折...
-
端侧AI算力需求推动智能手机内存技术演进 LLW低延迟宽DRAM方案进入视野
智能手机端侧AI应用对计算能力和数据吞吐量的要求持续走高,内存技术路线选择成为业界近期关注的一个方向。一种名为LLW的新型内存方...
-
本田前CEO川本信彦要求现任社长三部敏宏引咎辞职
本田汽车前首席执行官川本信彦近日现身东京总部,与现任社长三部敏宏直接对峙,要求其“引咎下台”。 90岁前掌门人当面提出最后通牒...
-
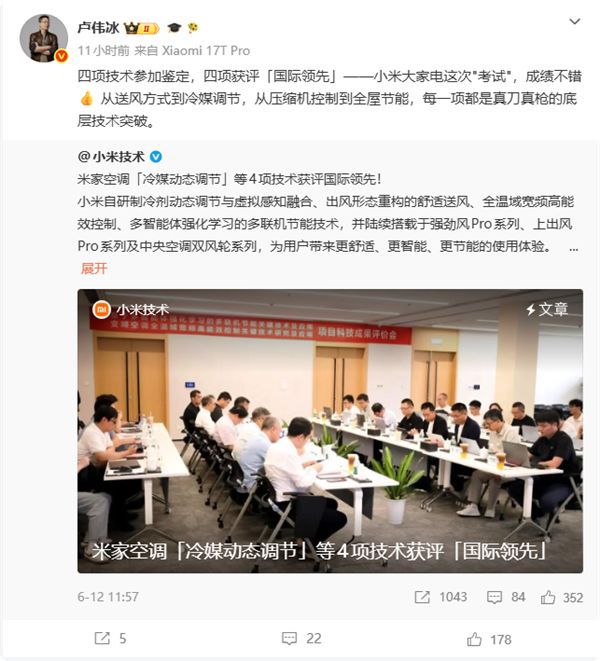
小米空调四项核心技术获评国际领先 卢伟冰称其为“底层技术突破”
6月16日,小米空调对外宣布,其四项核心技术经专业鉴定全部达到国际领先水准。小米集团合伙人、总裁卢伟冰对此进行点评,认为这四项成...
-
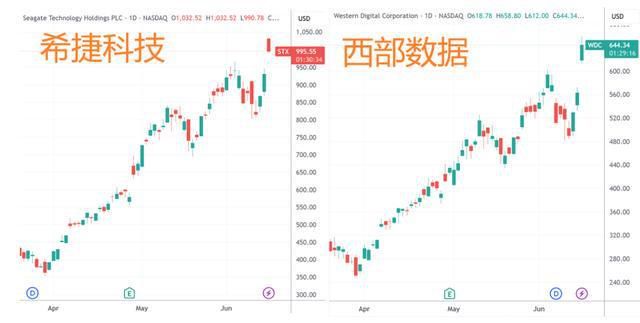
摩根士丹利报告:HDD短缺预计持续至2028年,上调希捷科技与西部数据目标价
财联社6月16日电,在周一发布的调研报告中,摩根士丹利表示硬盘驱动器(Hard Disk Drive,简称HDD)的短缺预计将持...
-
大疆发布Pocket 4双摄像头版本,延续紧凑型手持云台相机产品线
大疆在一个月前为Pocket 3推出后续机型Pocket 4后,其市场表现持续亮眼。据官方信息,该产品在多个电商平台至今仍处于缺...