x86生态系统咨询小组发布ACE规范1.15版本 集成原生矩阵乘法引擎与低精度格式
科技媒体Wccftech于昨日(6月19日)报道,x86生态系统咨询小组(EAG)正式发布ACE规范1.15版本。该版本通过引入原生矩阵乘法引擎和低精度格式,旨在提升x86架构在人工智能任务中的执行效率。
规范核心特性
ACE规范1.15版本的两项关键技术特性被明确:
- 原生矩阵乘法引擎:指处理器内部集成的专门用于加速矩阵乘法运算的硬件单元,这是神经网络计算的基础操作。
- 低精度格式:采用更少比特数表示数值,例如8位整数格式,可在保持模型精度的前提下大幅提升计算吞吐能力。
影响与背景
本次更新标志着x86生态系统在AI加速标准化方面迈出新的一步。通过将矩阵乘法引擎与低精度格式直接纳入架构规范,x86处理器有望在不依赖独立异构加速器的情况下更高效地执行AI推理任务。
ACE规范1.15版本由x86生态系统咨询小组(EAG)于6月19日正式发布,该小组由多家行业公司组成,负责维护x86架构的生态标准与演进路线。
业界观察人士指出,该规范为未来x86芯片的AI性能提升提供了统一的硬件接口基础,有助于软件开发者在跨平台场景下获得一致的加速体验。

英特尔与AMD联合成立EAG小组 推动x86架构标准化并推出ACE指令集
2024年,英特尔与AMD公司宣布联合成立EAG小组,旨在协调x86架构的未来演进方向,推动x86生态的规范化和标准化。这一合作被业界视为“世纪破冰”,两大芯片巨头首次在指令集层面展开深度协作。
ACE指令集:专为AI负载优化的新工具
作为EAG小组的首批成果,ACE(AI Compute Extensions)是一组专为加速人工智能与机器学习负载设计的x86指令集。其核心目标是优化矩阵乘法运算——深度学习中最频繁的计算操作——以及低精度数据格式处理。
矩阵乘法运算是深度学习模型中线性层和卷积层的基础计算单元,其效率直接影响模型训练与推理速度。
长期愿景:避免AVX-512碎片化问题
ACE指令集在设计之初即要求AMD与英特尔共同承诺支持,且未来产品更迭不会轻易废弃。这一机制旨在避免此前AVX-512指令集因各厂商不同实现导致的软件生态碎片化问题。
技术细节:新增图块寄存器与格式转换指令
在技术实现上,ACE在现有AVX向量指令基础上,新增了“图块寄存器”(tile register)状态,并定义了相应的数据移动与处理操作。图块寄存器可视为一种二维数据缓存结构,专门用于高效处理矩阵块数据。
ACE还纳入AVX10框架下的专用格式转换指令,进一步完善对低精度数据格式的支持。
部署路线图:AMD Zen 6与Zen 7将逐步引入
- AMD明确表示,Zen 6架构将引入“新AI数据类型支持”与“更多AI管线”;
- Zen 7架构则直接配备“新矩阵引擎”与“AI数据格式扩展”。
这一路线图表明,ACE指令集将从底层硬件层面全面赋能AI计算,逐步覆盖未来数代处理器产品。

ACE数据支持范围涵盖INT8至MX INT8等十余种格式
在数据支持范围上,ACE兼容多种整数与浮点数据格式,包括标准数据类型以及MX联盟定义的微缩格式。
标准数据类型
标准数据类型包含整数(INT8、INT32)与浮点(FP32、BF16、FP16)。此外,E8M0与FP8也作为标准浮点格式被纳入支持范围。
MX联盟微缩格式
MX联盟定义的格式通过重新分配符号、指数和尾数的位宽实现紧凑数值编码。对应子格式列表如下:
- MX FP8:SE5M2 / SE4M3
- MX FP6:SE3M2 / SE2M3
- MX FP4:SE2M1
- MX INT8
ACE支持的数据类型完整列表:INT8、INT32、FP32、BF16、FP16、E8M0、FP8,以及MX联盟定义的MX FP8(SE5M2/SE4M3)、MX FP6(SE3M2/SE2M3)、MX FP4(SE2M1)和MX INT8。
相关文章
-

铭凡 N5 MAX 迷你主机京东开售:搭载 AMD Ryzen AI Max+ 395 处理器,16999 元
6 月 20 日消息,铭凡(Minisforum)旗下 N5 MAX 迷你主机已正式在京东上架销售。该机定位高性能计算设备,核心...
-
微星推出31.5英寸4K 240Hz显示器 京东开售价5999元
微星品牌下型号为"MAG 321UP QD-OLED X24"的31.5英寸显示器已于6月20日在京东平台正式发售。该产品主打4...
-
魔声Open Ear AC229开放式耳机京东开售 定价209元起
6月20日,魔声旗下新款开放式耳机Open Ear AC229正式在京东平台发售。该产品官方定价为209元,部分区域在叠加国家补...
-
AMD确认将于2026年7月通过BIOS更新重新启用TSME功能
科技媒体Tom's Hardware于6月20日报道,AMD已确认将在下月(2026年7月)通过BIOS更新,在桌面锐龙9000...
-
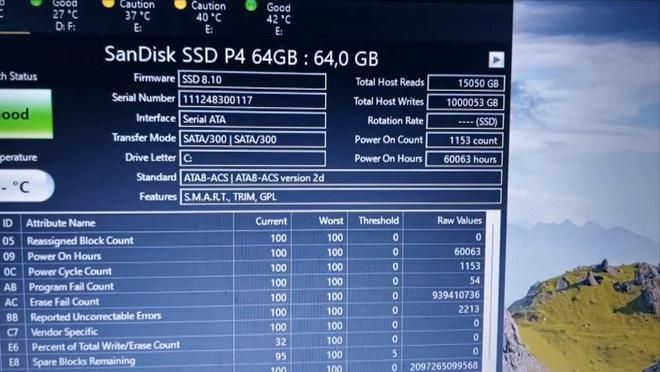
16年前64GB固态硬盘写入1PB仍存活 远超40TBW保修标称值
科技媒体Tom's Hardware 6月19日报道,YouTube频道WolfyTech发起的一项极限测试显示,一块16年前发...
-
绿联65W“小冰片”轻薄充电头上架 2C+1A设计定价129元
6月20日,绿联新款65W“小冰片”轻薄充电头在京东平台正式上架。这款产品采用2C+1A接口设计,厚度为14.5mm,官方定价1...
-
先马锋400侧透机箱京东上架:Mesh网孔设计配双16cm风扇,309元
6月20日消息,先马旗下锋400侧透机箱已在京东平台正式开售。该产品以大面积Mesh网孔侧板为主要设计元素,标配三颗ARGB风扇...
-
比亚迪发布城市领航无上限兜底政策 智驾责任归属成焦点
随着比亚迪官方宣布天神之眼城市领航功能推出“无上限”兜底政策,关于智能驾驶使用中违章扣分、罚款及事故刑事责任的承担问题,成为近...