第八届北京智源大会6月12日召开 罗福莉朱军等出席探讨人工智能议题
6月12日,第八届北京智源大会正式举行。会议汇集来自科技企业、高校计算机系及海外学术机构的数位人工智能领域专家,围绕当前技术核心动向展开交流。
跨机构专家阵容构成讨论主体
本次交流环节由四位具备不同机构背景的学者与从业者共同参与。小米集团MiMo负责人罗福莉代表科技企业研发端参与对话。
清华大学计算机系教授朱军同时担任生数科技创始人,负责相关技术落地与产业化衔接。
面壁智能联合创始人兼首席科学家刘知远以清华大学教授身份参与,负责前沿算法与智能系统架构的探讨。
南洋理工大学校长讲席教授、人工智能交叉研究院院长安波出席,其职务表明会议侧重跨学科研究与国际学术联动。
智东西报道指出,上述四位嘉宾在大会期间同台畅聊AI热点。
行业联动机制与技术探讨逻辑
大会通过汇集企业研发负责人、学术带头人、科技创业者与海外高校学者,构建出产学研交叉的对话模型。该结构将算法研究、技术商业化与交叉学科应用纳入统一讨论框架。
此次多主体集结的形式,反映出当前人工智能领域的技术演进已高度依赖跨机构协作与产学研深度绑定。

罗福莉评Claude Fable 5 指大模型与AGI迭代速度超预期
针对近期引发行业广泛关注的Claude Fable 5,业内观察者罗福莉对其技术演进路径作出公开解读。该模型的推出被视为Scaling策略持续推进后的自然结果。
核心维度拆解与演进路径
罗福莉指出,Claude Fable 5是预训练规模、数据规模以及强化学习三个维度持续扩展后的阶段性成果。Scaling(规模化扩展策略)在此指代算力、参数与数据的同步增长。从逻辑流程看,基础容量累积与策略微调优化共同推动模型迭代。
“其本质仍然是Scaling持续推进后的自然结果。”
- 预训练规模扩展:夯实模型底层参数与表征能力。
- 数据规模扩容:提升知识覆盖广度与语义理解深度。
- 强化学习环节:通过反馈机制实现行为对齐与策略收敛。
从业者观测与市场反馈
在技术维度不断突破的背景下,整体AI领域的演进节奏正在加速。罗福莉强调,大模型和AGI的发展速度实在太快,这一进程已直接传导至研发一线与行业观察层面。
技术迭代频率的跃升已改变从业群体的工作预期。当前市场主体的评估标准正随模型性能突破进行同步调整,相关技术路线的投入重心随之向高频优化方向倾斜。

专家解析AI模型Token消耗优化方向与自进化前提条件
近期,Token经济话题持续受到产业关注。多位学者围绕大模型代码生成效率、估值变化逻辑及人工智能自进化路径展开分析,指出技术迭代正逐步向降低资源消耗与构建垂直数据闭环转向。
模型任务中Token消耗呈下降趋势
在AI Coding与Agent应用推广过程中,历史阶段往往伴随大量Token的消耗。朱军指出,当前新版本模型在各类任务执行中的Token消耗实现下降,这一技术路径符合行业长期演进预期。
“新版本模型在任务中的Token消耗下降,这是一个正确方向。”
依据素材逻辑,Token消耗下降意味着单次任务处理的资源占比降低。模型在指令解析与代码生成环节的运行步长得到压缩,该技术路径符合效率提升预期。
垂直领域数据闭环加速应用迭代
刘知远分析Anthropic估值反超OpenAI的内在逻辑,认为代码方向的精准切入是核心因素。专业领域内形成数据闭环,能够有效推动AI应用进程。智能革命的本质在于替代人类机械性与重复性脑力劳动,而AI制造AI的核心驱动力仍回归于人。
“未来在专业领域里形成数据闭环,一定可以加速AI应用。”
基于现有业务场景构建的反馈机制,正在重塑模型训练的基础架构。垂直领域的代码优化与数据闭环建设,将直接缩短AI应用从研发走向实际生产环境的周期。
开放环境构成弱能力AI自进化的基础
安波针对AI自进化机制提出明确流程要求。当模型能力处于较弱阶段时,系统必须保持环境开放。数据飞轮的运转依赖外部交互输入以完成迭代,全封闭架构会阻断参数更新通道,导致技术演进难以行得通。
“AI自进化如果要行得通,一个重要的前提是环境不能完全封闭,如果完全封闭地搞数据飞轮,很难行得通。”
- 自进化机制需打破环境壁垒,保持交互开放性以维持循环。
- 封闭环境会切断数据飞轮的参数调优路径。
- 模型能力进阶与数据流通范围呈现直接关联。
相关文章
-

2026年高考结束引发暑期换机需求 手机市场迎来增长周期
6月12日,2026年高考正式落幕。伴随重要考试节点过去,消费者群体进入假期阶段,终端设备更新需求进入集中释放期,直接推动手机市...
-
英国Which?机构抽查15款充电器 指出七家电商平台产品缺标识
英国消费者权益组织Which?近日发布调查警示,指出可能致人死亡的山寨USB充电器仍在多个主流电商平台持续流通。该机构最新测试从...
-
华为终端宣布HarmonyOS 7开发者Beta启动 鸿蒙设备数突破6600万
6月12日,在2026年华为开发者大会(HDC 2026)现场,华为终端正式宣布HarmonyOS 7开发者Beta启动。此次版...
-
华为于6月12日发布鸿蒙生态一周更新速览
6月12日,华为官方发布鸿蒙生态一周更新速览。该通报以自然周为时间跨度,集中同步平台近期的技术迭代与生态建设动态。 周期化信息同...
-
昊铂S600正式上市 限时权益价17.99万元起
6月12日,昊铂品牌推出中大型轿跑SUV昊铂S600,新车共发布4款配置车型,官方指导价区间为19.99万元至21.99万元,叠...
-
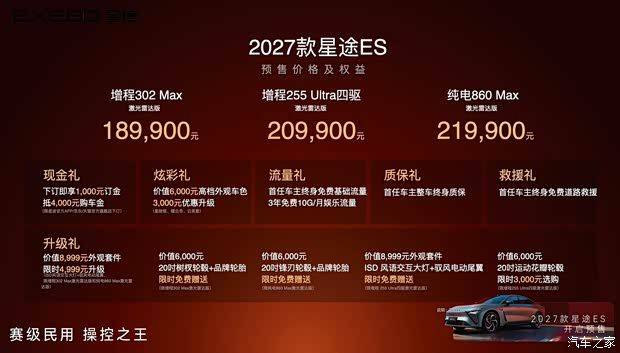
2027款星途ES开启预售 预售价18.99万元起 最高续航1685公里
6月12日,星途汽车宣布2027款星途ES正式进入预售阶段,共推出3款配置车型,预售价格区间为18.99万元至21.99万元。此...
-
AX电竞叛客推出GeForce RTX 5070夏日限定显卡
北京时间6月12日,IT之家消息显示,AX电竞叛客品牌正式推出了其GeForce RTX 5070夏日限定版新品显卡。这款产品被...
-
磐镭推出搭载AMD锐龙AI9 HX 470处理器的HO5迷你主机,售价7599元
近日,磐镭(PELADN)宣布对旗下HO5迷你主机产品线进行配置更新,推出了搭载全新AMD锐龙AI 9 HX 470处理器的版本...