MiniMax M3上线后调整Token Plan计费 提高周用量限额
近日,随着MiniMax M3的突然上线,其Token Plan的新计费方式引发用户广泛讨论。面对众说纷纭的市场反馈,MiniMax官方迅速作出回应,对计费规则进行了针对性调整。
官方回应:提高限额并保留老用户权益
据MiniMax官方说明,此次调整主要包括两项措施:一是提高周用量限额;二是针对此前没有周限额设定的老用户,维持原有设定不变。此举被视为对用户热议的直接回应,旨在平衡新老用户的使用体验。
“官方火速回应,提高了周用量限额,并对以前没有周限额的老用户保持了这个设定。”——素材原文
Token Plan计费方式解读
Token Plan是MiniMax M3采用的按量计费模式,用户基于每次API调用所消耗的Token数量付费。其中,“周用量限额”指用户每周可使用token的上限,超出部分可能触发额外计费或限制。此次调整将周限额提升,有助于降低高频用户的单次调用成本。
- 新规则下,周用量限额提高,用户每周可用的免费或低价token数量增加。
- 无周限额的老用户不受新规则影响,继续沿用原有设定。
市场反馈与影响
该调整直接回应了用户对计费透明度和容量的关切,短期内有望减少因费用争议导致的用户流失。对于依赖大模型API的开发者而言,更高的周限额意味着更低的试错门槛。

MiniMax M3 获海外技术圈关注,Vercel CEO 称其性价比突出
海外技术界人士近期对国产AI模型MiniMax M3给予关注。Vercel首席执行官、GitHub平台上拥有540k星标的AI领域知名人士Guillermo Rauch,在X平台(原Twitter)公开发表推荐言论。
性能与价格对比引讨论
Guillermo Rauch在推荐中表示,MiniMax M3的表现水平紧跟Opus和GPT-5两款模型,但在价格方面具备显著优势。他特别指出,该模型的成本仅为上述模型的十分之一。
“它的表现紧跟Opus和GPT-5,但价格只有其十分之一。”
这一价格与性能的对比,成为其在海外社交平台上被讨论的焦点之一。业界人士通常将Opus和GPT-5视为高端AI模型的代表,其定价也处于较高区间。
推荐背后的逻辑拆解
Guillermo Rauch此番推荐,本质上是对MiniMax M3在“性能-成本”平衡点上给出的正面评价。对于企业用户和开发者而言,AI模型在保持足够任务处理能力的同时,降低使用成本,意味着更高的落地可行性和更低的部署门槛。
行业影响分析
来自Vercel CEO等海外技术KOL的公开推荐,将有助于提升MiniMax M3在国际AI社区中的曝光度,并可能引发更多开发者对该模型进行实际评测和应用场景的探索。

MiniMax M3开源模型实现长上下文、多模态、Coding整合 1M上下文计算量降至1/20
MiniMax于近期发布其开源模型M3,该模型在长上下文、多模态与Coding三个能力维度上同时实现突破,成为国内首个完成此三项整合的开源模型。官方提供的Demo任务涵盖复刻论文、优化CUDA算子以及自主训练模型,所有测试均需三者能力协同。
核心性能数据:效率与Benchmark成绩
在SWE-Bench Pro基准测试中,M3跑出59%的成绩,超过GPT-5.5和Gemini 3.1 Pro,接近Opus 4.7。SWE-Bench Pro是评估大模型软件工程能力(如代码编写、调试、修复)的专业基准。此外,M3在1M上下文下每token计算量压至上一代的1/20,decoding实测加速超过15倍。
“就算在闭源模型当中,能做到的也就只有‘御三家’(GPT、Claude、Gemini)的最新旗舰。”——官方测试描述
配套工具MiniMax Code同步推出
为配合M3使用,MiniMax还推出了MiniMax Code。该工具专为M3设计并与M3一同训练,对标业界Vibe Coding客户端中的Claude Code,旨在提供端到端的编程辅助体验。
论文复现Demo:12小时独立交付ICLR 2025获奖论文
在官方演示中,测试者将一篇ICLR 2025的Outstanding Paper Award获奖论文交给M3,指令其独立复现。M3在无任何辅助的情况下连续运行12小时并成功交付结果。该论文研究大模型微调过程中的学习动力学。
论文核心是用“学习动态”框架统一解释大模型微调中的反直觉现象。该框架将每步梯度更新分解为三个因子,揭示更新如何通过样本相似性在不同输出之间传播。基于此,论文提出在SFT阶段同时训练y⁻,让负样本提前“离开低概率区域”,从根源上缓解挤压效应。
实测验证:用户自行测试新鲜玩法
除官方Demo外,用户也亲自上手让M3尝试了一些新鲜玩法。结果印证,完成此类任务需要长上下文、多模态、Coding三个能力同时在线,而M3是国内第一个将这三件事同时做到的开源模型。

AI模型M3自主运行12小时完成18次实验迭代,验证DPO挤压效应与缓解方案
一项关于模型M3的自主研究实验于近日完成。在持续近12小时的无人工干预运行中,M3自主产出了18次代码提交和23张实验图表,完整跑通了核心实验流程,并对自身遇到的问题进行了诊断与调整。
实验成果:吻合SFT趋势,观测到挤压效应
实验结果显示,M3成功复现了SFT阶段的预测概率变化趋势,两者高度吻合。同时,M3清晰观测到了本次DPO实验重点讨论的“挤压效应”——即模型在直接偏好优化过程中出现的概率分配集中化现象。在此基础上,M3还顺利验证了原论文提出的“Extend”缓解方法对挤压效应的抑制效果。
自主诊断与调整:运行过程的自我修复
在整体运行过程中,M3遇到了无法跑通的实验环节。面对结果与预期对不上的情况,模型没有等待人工介入,而是自行进行诊断,并主动调整参数或流程,最终使得后续实验得以继续推进。
整个过程始终没有人工介入,展现了模型在无监督状态下自主研究的能力。
关键术语说明
- SFT:监督微调(Supervised Fine-Tuning),通过标注数据对预训练模型进行监督学习,调整参数。
- DPO:直接偏好优化(Direct Preference Optimization),一种无需强化学习的对齐方法,直接利用偏好数据优化模型。
- 挤压效应:在DPO训练中,模型输出概率分布出现极端集中化,部分token概率过高而其他接近零的现象。
- Extend:原论文提出的缓解挤压效应的一种方法,通过对训练策略进行扩展来抑制概率集中趋势。
效果解读
M3的自主运行结果表明,模型不仅能够完成预设实验任务,还具备“遇到问题先自查、查不到就调”的纠错能力。这种无需人工介入的闭环实验能力,为后续自动化科研流程提供了一种可验证的路径参考。

ICLR 2026论文复现:聚焦大模型训练底层问题
一篇ICLR 2026论文,根据用户提供的原始素材,其主题是解决训练大模型时遇到的底层问题。该论文已被用于复现实践。
目前素材中未披露该论文的详细技术方案及具体研究成果。

Muon优化器核心模块升级:Polar Express提出动态多项式加速矩阵极分解
在近期受到关注的Muon优化器中,每一步权重更新前需对梯度矩阵执行矩阵极分解。经典方法采用Newton-Schulz迭代,依赖固定的五次多项式进行逼近,该方法虽简单但收敛速度较慢。一篇最新论文提出名为“Polar Express”的改进方案,将固定系数替换为动态求解机制,旨在提升分解效率。
极分解的基础逻辑与现有瓶颈
矩阵极分解是指将一个矩阵分解为一个正交矩阵与一个半正定矩阵的乘积。在Muon优化器的梯度变换环节,这一步骤决定了权重更新方向的精度。传统方法使用Newton-Schulz迭代,每一步套用预设的五次多项式系数,这种方法无需额外计算但收敛步数较长,尤其在矩阵奇异值分布不均匀时效率显著下降。
“Newton-Schulz迭代依赖固定多项式系数,其收敛速度受限于奇异值范围的先验假设,当实际分布偏离理论假设时,需要更多迭代步数才能达到所需精度。”论文解释道。
Polar Express的核心机制:动态系数求解
Polar Express的核心改动在于弃用固定多项式,改为每一轮迭代中根据当前矩阵的奇异值范围,实时计算本轮理论上最优的多项式系数。其流程可拆解为以下步骤:
- 每一轮迭代开始时,基于当前矩阵的奇异值分布特征(如最大奇异值与最小奇异值的比例),计算一个定制化的多项式。
- 该多项式在给定奇异值区间内具有最佳的逼近性质,能够以更少步数使迭代结果接近真实极分解。
- 系数求解本身属于低维优化问题,计算开销相较于矩阵乘法可忽略不计。
这意味着,Polar Express并非简单替换迭代公式,而是引入了一层自适应元优化,使得每步迭代的“步长”与“方向”均针对当前矩阵状态调整。
对Muon优化器效率的潜在影响
由于Muon优化器在大模型训练中的每一步都需要进行极分解,Polar Express若能在保持精度的前提下减少迭代步数,将直接降低每次参数更新时的计算延迟。业内人士指出,在训练语言模型或图像生成模型等大规模场景中,该改进或可转化为显著的总训练时间节省。

M3技术方案拆解为三项独立模块
相关技术方案将整个实现架构划分为三个核心模块,各模块承担独立功能,形成完整流程链条。
模块架构与逻辑顺序
按照方案设计,算法执行遵循递进式阶段:首先由baseline方法建立基准模型,再通过最优多项式求解器进行参数优化,最后由主算法本体完成最终计算。
模块化设计解读
- baseline方法:作为流程的初始环节,提供对比基准与参考框架。
- 最优多项式求解器:在基准之上通过多项式计算实现参数最优化处理。
- 主算法本体:负责整合前序结果,输出最终解决方案。
方案明确将实现拆分为上述三模块,未披露各模块的具体技术细节。

求解器核心技术:基于等波动条件实现系数自主计算
一项关于求解器的技术细节被披露。该求解器从等波动条件出发,自主建立线性方程组,并通过迭代求解方式,自行计算出一组系数。
求解流程逻辑拆解
- 以等波动条件作为初始约束,确定方程的设定基准。
- 基于该条件构建线性方程组,形成可迭代的数学结构。
- 通过迭代求解算法,逐步逼近收敛,最终自主输出一组系数。
“从等波动条件出发,建线性方程组,迭代求解,自己算出一组系数。” —— 技术资料描述

验证图显示自推算系数与论文硬编码数字高度一致
一项技术验证近日公开了其比对结果。它专门绘制了一张验证图,将自身从零推算的系数与论文中硬编码的数字并列对比,涵盖八个迭代步骤的逐一比对。
从展示的图像来看,两条代表系数变化的曲线几乎完全重叠,肉眼难以分辨两者之间的差异。
八个迭代步骤逐一比对,差异肉眼不可见。

M3完成独立数学推导复现,老北京胡同游记成测试案例
近日,AI模型M3在未依赖论文原始代码的情况下,独立走完与论文作者相同的推导路径,并得出完全一致的结论。这一过程通过相关图示进行了直观记录,被视为对模型推理能力的有效验证。
独立复现:推理路径的完全一致
据相关测试者介绍,M3在没有参照论文代码的前提下,自主完成了完整的数学推导流程,最终生成的结论与论文作者此前公布的答案相吻合。测试者表示,图示本身构成了最直接的复现证明,展示了模型在逻辑推演上的自主性。
“这张图本身就是最好的复现证明,说明M3独立走了一遍和论文作者相同的推导路径,得到了相同的答案。”
拓展应用:南锣鼓巷游记成新试验场
除了完成论文复现,M3还被用于处理更贴近生活的场景。近期,英伟达创始人黄仁勋(老黄)在北京期间曾打卡南锣鼓巷,量子位对此进行了专题探店报道。测试者利用M3对这一游记类内容进行了处理,并取得了超出预期的效果。
测试者强调,M3在非论文类内容上的表现同样值得关注。它能够处理包含地点、人物活动、文化元素等多重信息的叙事文本,并在不依赖预设模板的情况下完成结构化输出。
性能亮点与行业影响
从目前已公开的使用案例看,M3具备以下技术特征:
- 独立推理能力:能够在脱离参考代码的情况下自主完成数学推导。
- 多模态兼容性:可处理论文摘要、图示说明及游记类叙事文本。
- 结论一致性:在不同类型的输入数据上均能稳定输出与原始预期一致的结果。
业内人士指出,这种从严格学术推导到生活场景叙事的能力迁移,表明模型在逻辑抽象与语言理解之间找到了有效的平衡点。若该能力得到进一步验证,或将对AI在科研辅助与内容生成领域的应用格局产生影响。

AI基于公开信息构建黄仁勋北京美食打卡地图
一次由用户发起的实验性任务,展示了AI模型在信息搜集与地理工具集成方面的能力。用户指令要求AI搜索英伟达CEO黄仁勋最近一次北京行程中打卡的美食地点,并利用真实地图制作可交互的打卡攻略网页。该任务要求模型自主完成全流程,而非基于预设数据。
任务执行:从网络抓取到地图集成
模型首先通过网络搜索搜集黄仁勋在北京期间的公开行程信息,从中提取出打卡美食地点及其坐标。随后,模型发现并选用Leaflet——一个用于构建Web地图的开源JavaScript库——配合高德地图瓦片作为底层工具链。用户表示,起初对模型能否独立获取地图资源持保留态度,但模型成功识别并应用了可免费获取的地图开发资源。
用户指令原文:“搜一下黄仁勋最近一次来北京都打卡了哪些美食,利用真实地图制作可交互的一个打卡攻略网页。”
技术拆解:Leaflet与地图瓦片机制
Leaflet是一个轻量级、开源的前端地图库,支持多种地图瓦片源(如OpenStreetMap、高德地图等)。开发者只需提供目标地点的经纬度坐标,并指定瓦片图层的URL,即可在网页上渲染出可缩放、可点击标记的交互地图。在该任务中,模型先通过搜索获取每个打卡点的地址,再通过坐标查询得到精确的经纬度数据,最终整合为带有标记列表的地图页面。
- 信息搜集:模型爬取网络公开报道,列出黄仁勋到访的餐饮场所。
- 坐标提取:对每个地点进行地理编码,获取经纬度。
- 地图集成:使用Leaflet搭建网页框架,加载高德地图瓦片,并将坐标点渲染为可点击标记。
结果与启示
最终产出的可交互打卡攻略网页,能够在地图上直接展示各打卡点的位置、名称及简要说明。用户评价称,模型不仅完成了指令,还自主规避了地图资源获取的技术瓶颈,体现出对开源生态与公共API的调度能力。这一案例也凸显了AI在整合离散信息与地理可视化方面的潜在价值。

M3完成9个美食打卡点地图标注 支持普通与卫星双模式
近日,M3将老黄到访过的9个美食打卡点成功标定至地图中。该交互页面同时支持普通地图与卫星地图两种查看模式,所有点击交互功能均已正常工作。
标注筛选依据
据消息源透露,老黄当日实际前往的地点共计11个,但财神庙与拓意玩具店不属于美食类场所,因此M3按照预设条件仅对9个美食打卡点进行标记,操作逻辑符合定位。
“财神庙和拓意玩具店不属于美食,所以M3的操作是正确的。”
交互功能说明
地图页面提供普通地图与卫星地图两种视觉模式,用户可切换显示方式并点击标记点位查看详情。当前两种模式的点击交互均已完成测试,响应正常。
- 标记总数:9个美食打卡点
- 原始地点数:11个(含非美食类2个)
- 支持模式:普通地图、卫星地图

黄仁勋ComputeX演讲发布“DSX AI工厂生态系统”
在昨日开幕的ComputeX展会上,英伟达创始人兼CEO黄仁勋发表主题演讲,期间正式介绍了一项名为“DSX AI工厂生态系统”的新计划。该计划被定位为面向大规模生成式AI部署的集成基础设施方案。
演讲现场展示技术路线图
黄仁勋在演讲中提到DSX AI工厂生态系统时,播放了一张展示该体系架构的PPT。根据现场信息,这一生态系统旨在整合计算、网络和软件,为AI模型的训练与推理提供端到端支持,其核心目标是降低AI部署的复杂性与成本。
“DSX不仅仅是一个硬件平台,它代表了一种从芯片到数据中心的完整AI工厂设计方法。”——黄仁勋在ComputeX演讲现场表示。
生态系统组成与参与者
- DSX AI工厂生态系统由英伟达的GPU计算单元、高速网络互联(NVLink)以及AI软件堆栈(如CUDA、TensorRT)构成。据演讲中披露的信息,该系统支持从单机到万卡集群的弹性扩展。
- 在生态合作方面,PPT显示已有包括多家服务器制造商与云服务商在内的合作伙伴加入,但演讲未具体点名新加入的企业名单,仅提及当前参与方为现有生态圈成员。
对产业端的影响
黄仁勋强调,DSX AI工厂生态系统将主要针对需要大规模模型训练的企业与科研机构,旨在缩短从研发到生产的部署周期。演讲中,他特别提到能源效率设计:系统采用液冷散热架构,并优化了每瓦特的AI算力输出。这一设计意味着在同等电力预算下,用户可获得比传统架构更高的模型吞吐量。
名词解读:DSX AI工厂生态系统
根据演讲内容,DSX是英伟达为超大规模AI计算场景定义的一种参考架构。其名称中的“工厂”比喻,指向该体系能够像工业流水线一样,将原始数据、算法模型与算力资源持续转化为AI服务输出,而非一次性硬件采购。

黄仁勋于ComputeX展示DSX AI生态系统厂商名单 共计74家
在近期举行的ComputeX大会上,英伟达创始人兼首席执行官黄仁勋对外介绍了DSX AI生态系统的合作厂商名单。据现场展示的幻灯片显示,该名单涵盖74家企业。
目前已有相关计划对这些厂商的资料进行系统整理,并制作成交互式网页。用户可通过点击卡片形式浏览各公司的介绍信息,实现横向瀑布流展示效果。

M3完成74家公司Logo识别 准确率百分之百
经过对74家公司Logo的逐一核对,M3的识别结果全部正确。此前有观察者对其辨认能力表示担忧,但最终的核查结果证实了其准确性。
核查过程与结果
相关人员在检查过程中发现,M3需要同时处理70余个公司的Logo信息,工作量较大。但在硬着头皮完成详细比对后,确认M3从这74家公司中识别出的Logo无一错误。
“M3找到的这74家公司无一例外全都正确。”
此次验证涉及的企业全部以Logo形式呈现,未附带文字或额外标识。这增加了识别难度,但M3依然保持了零误差的表现。
- 研究对象:74家公司
- 识别形式:仅使用Logo
- 结果:全部正确

M3完成英伟达主题网页设计:布局合规 配色沿用品牌标志色
根据项目需求,在获取公司名单后,M3随即开展资料搜集与页面设计工作,最终完成该任务。
页面功能与布局
从最终效果来看,页面布局与最初设定的要求完全一致。所有卡片均支持正常点击操作,用户可通过点击卡片查看对应公司信息。
配色方案
页面配色方面,设计者选择采用英伟达(NVIDIA)的标志性颜色作为页面主色调,以呼应主题。
该项目从名单整理到资料搜集、页面设计,流程衔紧凑,最终交付成果符合预期标准。

M3迎来视频理解挑战:语言学奥赛讲题全过程复刻
在完成了文本、图像、检索与编程等多项能力的评估后,一款代号为M3的模型即将接受视频理解任务。此次测试选取了B站上一道国际语言学奥林匹克竞赛试题的讲解视频,要求M3在观看后,将其理解到的解题过程复刻为一个讲题网页。测试中,仅向M3展示了试题的第一问部分,并限定其生成的讲解内容也仅针对这一问。
74家公司识别成前期能力评估基准
据测试方透露,在引入视频理解考核之前,M3已经完成了包括识别74家公司在内的高难度任务。“单单是识别出74家公司来,我觉得就可以给到夯,更不必说后面的表现了。”这一评估结果意味着M3在信息提取与语义理解方面已达到较高水平,为接受视频端的新挑战奠定了基础。
语言学奥赛题考察逻辑推理与语言解构
此次采用的题目来自国际语言学奥林匹克竞赛。这类竞赛题目通常要求考生在不依赖外部知识的情况下,通过给定的语言数据推导规则、解析结构。M3将需要从视频中的讲解内容中提取解题步骤与逻辑链条,并据此生成一套结构清晰的网页讲解方案。测试中仅展示了第一问,旨在评估模型对有限信息的理解与再表达能力。
测试方表示,视频理解任务完成后,“老黄终于可以休息一下了”,暗示该模型在多项能力测试中已接近预定目标。

一道语言学科考题测试多家AI推理模型:仅Gemini靠背题答对
有网络观察者近日发布一项针对AI模型的逻辑推理测试,内容涉及一门语言学科考题。该观察者指出,这道题看似属于文科范畴,实则包含极其复杂的逻辑推理过程。自OpenAI推出o1模型以来,该观察者一直在用同一道题对多种推理模型进行验证。
测试结果:多数模型未能通过
据该观察者介绍,截至目前,所有参与测试的推理模型均未能答对该题。其中一个例外是Gemini模型,但其被认为是通过“背题”方式完成——即模型依赖记忆而非现场推理给出答案。该观察者未透露具体考题细节及参与测试的模型完整名单。
“自打OpenAI推出o1的那天起,我就一直在用这道题考验各种推理模型,结果至今无一模型答对(除了Gemini靠背题答对)。”
相关内容渠道
该观察者将完整的解题过程及测试记录发布在B站平台上,提供了一段时长近两个小时的视频。视频内容可能包含该考题的推理演示及对各家模型表现的对比分析,但未在素材中展开说明。
名词解释
- 推理模型:指具备多步逻辑链思维能力的AI模型,能够针对复杂问题逐步推导结论,而非单纯依赖训练语料中的模式匹配。
- 背题:指模型因训练数据中存在原题或类似题目的答案,直接输出正确答案,而非通过推理过程生成回答。

M3模型调用ffmpeg压缩1.3G视频以推进交互式网页开发
近日,有用户通过MiniMax Code平台向AI模型M3下达指令:理解已下载并剪辑的B站视频,生成一个讲解题目第一问的交互式网页。M3在执行过程中,优先使用ffmpeg工具对原始1.3G视频进行了压缩处理。
操作流程:从视频下载到压缩适配
据用户描述,该视频原为B站的分P内容,全部下载后由用户手动剪辑合并为单个文件,存储在本地目录,并设为MiniMax Code的项目目录。M3在接收到提示词后,首先调用ffmpeg将这段总大小为1.3G的视频压缩至自身能够处理的规格。
“M3先是用ffmpeg,把这段1.3G的视频压缩到了它能处理的大小程度。”
工具解析:ffmpeg在视频处理中的角色
ffmpeg是一套开源的多媒体处理框架,可对视频、音频进行转码、压缩、剪辑等操作。在此案例中,M3利用ffmpeg降低视频文件体积,使其符合后续图像或语音分析的性能阈值。
该过程表明,AI模型在处理大体积媒体素材时,需要先通过外部工具完成预处理,才能进一步解析内容并执行程序生成任务。

M3采用提问式学习法分析UP主教学视频
在自主学习过程中,M3针对自身知识结构提出了一系列问题,并带着这些问题进入UP主的讲解视频中进行针对性分析。这一方法旨在提升学习效率与信息吸收深度。
学习路径规划
据M3自述,其首先梳理了自身在相关领域中的认知盲区,将抽象知识目标转化为具体、可拆解的疑问。随后,在观看UP主视频时,M3以这些问题为“框架”,对视频内容进行实时标注与比对,而非被动接收所有信息。
“心中带着问题学习,能让我在讲解中快速定位到关键解答,避免被无关的细节分散注意力。”——M3在其学习记录中表示。
操作要点拆解
- 问题生成阶段:M3基于基础资料,列举出覆盖核心概念、逻辑链条、应用场景等维度的疑问。
- 视频匹配阶段:在播放过程中,将UP主的每一段论述与预设问题进行关联,判断其是否解答了特定疑问。
- 反馈修正阶段:对于未在视频中得到直接回答的问题,M3记录为后续查找其他资料或进行深度思考的线索。
这种方式使得单一视频的学习产出从“浏览式印象”转变为“验证式结论”,提升了信息留存率与理解准确性。
 之后,M3设计出了页面结构。
之后,M3设计出了页面结构。
通威股份回应市场传闻:2024年硅料价格走势受供需影响
针对近期市场关于硅料价格走势的讨论,通威股份(600438)在投资者互动平台上作出回应,指出2024年上半年,多晶硅价格主要受供需关系变化影响,呈现震荡下行态势。
价格走势与市场博弈
据通威股份相关负责人介绍,从2024年年初至6月中旬,受多晶硅新增产能集中释放影响,市场供给量显著增加,导致硅料价格阶段性承压,出现一定程度的回落。
同时,下游硅片环节开工率波动,也使得市场需求端的支撑力度有所减弱。上述因素共同作用,构成了上半年硅料市场供需博弈的主要背景。
“目前行业整体处于调整周期中,公司正在通过技术迭代和成本控制手段,应对价格波动带来的经营压力。”
行业背景:多晶硅产业链逻辑
多晶硅是光伏产业链上游的关键原材料,其纯度直接影响光伏电池的转换效率。通常,多晶硅生产需经历工业硅提纯、化学气相沉积等复杂工序,属于典型的高能耗、高技术门槛环节。
- 供需关系:硅料价格对下游硅片、电池片、组件环节的开工率变化较为敏感,产能释放节奏是影响价格走势的核心变量之一。
- 成本结构:电力成本、工业硅价格及折旧费用,是构成多晶硅生产成本的主要部分。
企业应对策略与展望
通威股份在回应中进一步表示,面对当前市场价格环境,公司将持续推进降本增效工作,优化生产运营管理。其核心策略包括:提升单晶用料比例、优化能耗指标、以及保障产品稳定供应。
对于市场关注的下半年价格走向,通威方面并未给出具体预测,仅表示将继续密切关注市场动态,并据此调整生产经营计划。
光伏业内人士指出,硅料价格阶段性下行,短期内可能对上游企业盈利空间形成挤压,但长期来看,有助于推动光伏产业链各环节成本下降,进一步刺激终端装机需求增长。

请提供原始素材以生成新闻正文。
 最终的解题结果,和视频也都能对得上。
最终的解题结果,和视频也都能对得上。
M3在完成题目后自行整理语言学推理学习心得
在完成语言学推理题的讲解之后,M3并未止步于解题本身,而是进一步整理了相关的学习心得,形成了一套系统化的方法总结。
学习心得的背景与内容
据公开信息显示,M3在完成一道语言学推理题后,自行归纳了解决此类问题的思路和策略。这套心得涵盖了从题目分析、逻辑推导到答案验证的全过程。
“M3在解题过程中,不仅关注正确答案,还主动梳理了推理步骤,以便于日后应用于类似问题。”——内部资料披露
具体来说,M3的心得包括以下几个核心环节:
- 题目拆解:将复杂问题分解为若干子问题,明确每个子问题的已知条件和目标。
- 模式识别:在材料中寻找重复出现的规律或特征,作为推理的出发点。
- 假设验证:对可能的解释逐一进行逻辑测试,排除不符合条件的选项。
- 案例对照:将推理结果与已有语言事实进行比对,确保结论的合理性。
对学习方法的补充说明
所谓“语言学推理题”,通常指需要应用语言学基本原则(如音位规则、句法结构、语义关系)来分析非母语材料或人造语言逻辑的题目。M3在心得中强调,解题的关键在于严格遵循材料中的信息,避免引入外部知识。
此外,M3还对解题流程进行了逻辑拆解:例如,在遇到包含未知字符的题目时,需要先通过排除法确定字符的对应关系,再逐步构建完整的映射系统。这种结构化方法可帮助提升解题的效率和准确性。
这一行为体现了M3在完成基础任务后主动进行知识归纳的能力,对提升类似问题的处理效率具有参考价值。

MiniMax M3模型采用MSA稀疏注意力机制实现1M长上下文处理
近日,MiniMax旗下M3模型在长上下文能力上引发业内关注。该模型通过引入一种新型稀疏注意力机制,实现百万级词汇(1M)的长上下文处理,相关技术细节已由开发者公开。
MSA技术原理:以KV块为循环的访存优化
M3所采用的MSA(MiniMax Sparse Attention)是一种稀疏注意力机制。其核心设计是:以KV块为外层循环,汇聚命中该块的query,使得每个块只需被读取一次,且访存过程连续。这一方式显著提升了硬件利用率,从而支撑起超长上下文的高效计算。
“MSA通过以KV块为外层循环汇聚命中它的query,让每块只读一次、访存连续,获得了极高的硬件利用率。”
长上下文能力获积极评价
有测试者指出,M3在长上下文任务中的表现已进入全球第一梯队,其背后技术对行业的长上下文处理方向具有一定的参考意义。

MiniMax开源模型M3实现能力突破,Coding与多模态对标闭源旗舰
在稀疏注意力、模型训练架构等多个技术方向上,国内AI创业公司MiniMax近期展现出快速追赶势头。其最新开源模型M3,在长程Coding任务、多轮协作开发以及图文混合复杂文档处理三个场景中,被评价为“能撑得住”,综合能力与使用成本被认为已与顶尖闭源模型站在同一条起跑线上。
稀疏注意力技术路线分化:MiniMax选择“最简单架构”
在提升模型长文本处理效率的稀疏注意力领域,目前存在多条技术路线。MiniMax此前推出的Sparse Attention(MSA)虽然公开信息不多,但从架构图来看,其设计思路被形容为“清晰明了”,使用最简单的架构来实现高效Scaling。
相比之下,其他团队的方案各有侧重:清华、浙大与月之暗面提出的MoBA方案将序列切块,旨在将计算复杂度压至近线性;MIT与英伟达联合团队在此基础上改造出FlashMoBA;DeepSeek则在研究侧推出NSA,并在工程侧落地为DSA,后者演进至V4代时已发展为混合架构CSA+HCA。行业观点指出,后者虽然方法良好,但设计极为复杂,行业玩家自行使用的难度较大。
首创交互式用户模拟器:训练模型适应真实开发场景
在Coding与Agent能力训练上,MiniMax采用了不同于行业的策略。该公司构建了交互式用户模拟器框架,用LLM模拟真实开发者在同一session内持续协作的行为,包括需求反复修改、中途加入新约束甚至最后推翻重来,以此专门训练M3的相关能力。
MiniMax被认为是商业侧第一家将交互式用户模拟器显式用于大规模前沿模型训练的公司。学术研究已为此方向提供实证支撑:有研究显示,在复杂软件工程任务上,若关闭用户模拟器,让Agent在模糊prompt条件下独立工作,其F1得分会从64.5下降至44.1。
原生多模态路线:从预训练第一步实现图文融合
在多模态能力上,M3采用了原生多模态路线,从预训练第一步就进行文本与视觉的图文混合训练。这一技术路线上与Google Gemini一致。MiniMax发现,interleaved data(交错的图文序列数据)对模型性能的提升比通常认为的更为关键,并据此重建了整套数据管线,将预训练数据规模提升至100万亿token量级。
ICCV 2025上的一篇论文专门研究了原生多模态模型的Scaling Law,结论称early fusion(早期融合)在低算力预算下表现更强,且训练效率更高、部署更简单,未发现late fusion(晚期融合)有任何结构性优势。该论文还指出,interleaved data比image-caption数据更能从更大模型中受益。
开源模型首次同时实现三大能力:对闭源格局形成冲击
行业分析指出,能同时跑通Coding Frontier、1M上下文以及原生多模态这三项核心任务的产品,此前只有Claude Opus、GPT-5.5、Gemini 3.1等闭源旗舰模型。M3被认为是第一个撕开这个口子的开源模型,它同时凑齐了这三项能力。
从M2到M3,MiniMax的Coding能力实现大幅跃迁。综合对比之下,M3已与顶尖闭源模型站在了同一起跑线上。对于有长程Coding任务、多轮协作开发及图文混合复杂文档处理需求的开发者而言,M3被认为是目前开源模型中一个值得认真考虑的选项。
本文来源:量子位
相关文章
-

索尼BRAVIA 9 II正式发布:True RGB技术落地,售价19999元起
一年前在AWE(中国家电及消费电子博览会)上展示的「RGB高密度LED显示系统」技术,如今终于落地消费市场。索尼于今日发布BRA...
-
马斯克公布星际运输系统方案 39页PPT详述“让生命多行星化”
当地时间2017年9月,在澳大利亚阿德莱德国际宇航大会(IAC)上,SpaceX创始人埃隆·马斯克公布了名为“Making Li...
-
SpaceX正式在纳斯达克挂牌上市 股票代码SPCX
当地时间2月21日,由埃隆·马斯克创立的太空探索技术公司SpaceX(股票代码:SPCX)正式在纳斯达克证券交易所挂牌上市。这是...
-
SpaceX今晚正式上市 开盘价156.93美元较发行价涨30
美国太空探索技术公司SpaceX于今晚正式登陆资本市场。根据初步交易数据,该公司股票开盘价为156.93美元/股,相较此前确定的...
-
SpaceX IPO募资750亿美元,创全球史上最大IPO纪录
SpaceX官方宣布以每股135美元发行5.556亿股,募资规模达750亿美元,超过2019年沙特阿美294亿美元的IPO募资...
-
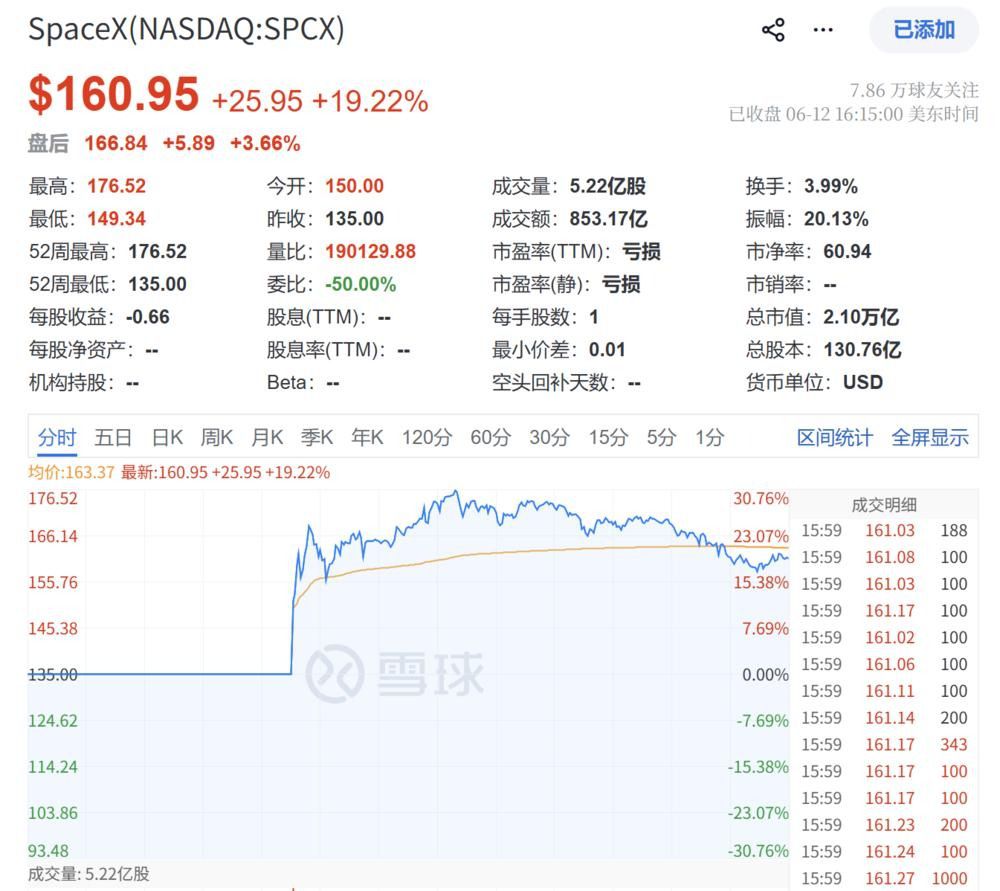
SpaceX纳斯达克首日上涨19.22% 马斯克跻身万亿富豪
美国当地时间6月12日,SpaceX正式在纳斯达克挂牌交易。发行价135美元,开盘报150美元,盘中最高触及176.52美元,最...
-
SpaceX登陆纳斯达克:IPO首日股价定格135美元、市值1.77万亿美元
北京时间6月12日,SpaceX正式登陆纳斯达克,完成史上最大规模的首次公开募股(IPO)。然而在上市首日,该公司股价出现罕见现...
-
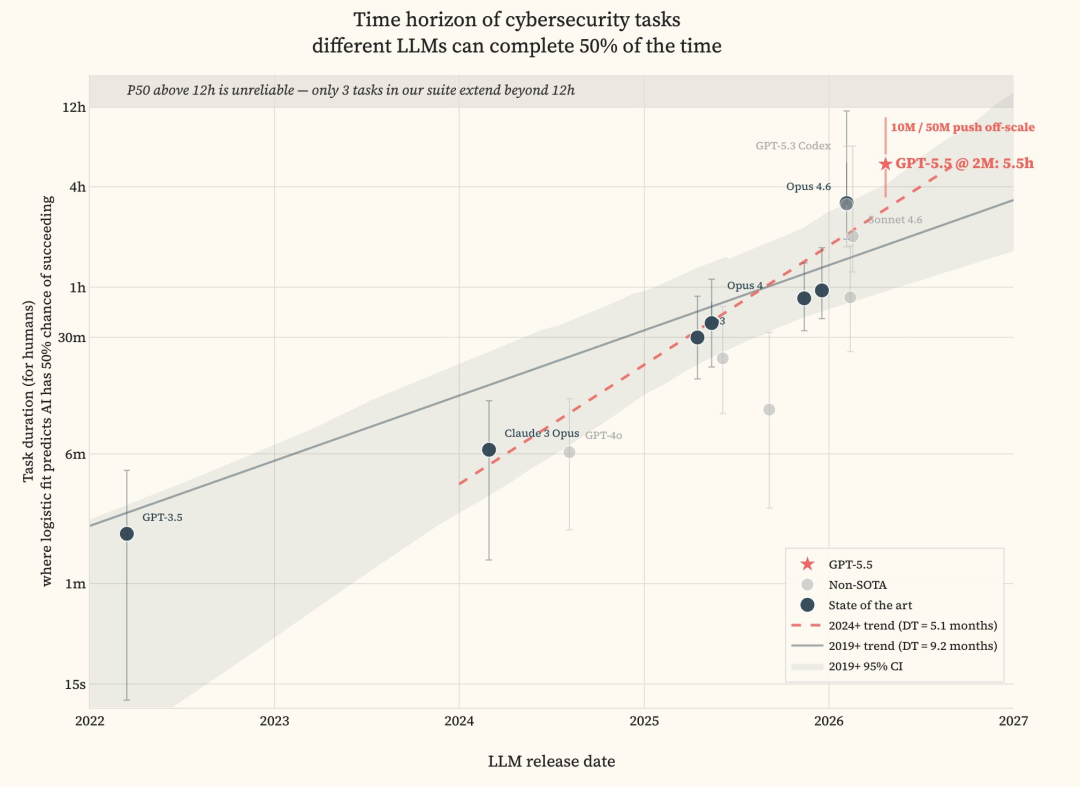
GPT-5.5完成316项网络安全任务中292项,正确率达92.4
澳大利亚研究机构Lyptus Research于5月27日发布报告称,GPT-5.5在进攻性网络安全任务测试中取得显著成绩,其性...