深入eBPF内核:从原理到实践,手把手实现一个低损耗的云原生网络观测器
0
摘要
随着云原生技术的发展,传统基于
iptables或应用层埋点的可观测方案在面对百万QPS的高并发场景时,往往面临巨大的性能开销。eBPF(Extended Berkeley Packet Filter)技术的出现,允许我们在不修改内核源码的情况下,将沙盒程序动态加载到内核中运行。本文将摒弃浅显的Hello World示例,深入探讨eBPF的底层Hook机制,并通过Go语言+C语言混合编程,实现一个能够实时捕获TCP连接延迟、追踪Socket生命周期的高性能内核观测器。1. 引言:为什么eBPF是运维体系的下一代基石?
在传统的APM(应用性能监控)系统中,我们通常需要注入Agent来拦截系统调用或依赖
/proc文件系统的轮询。这种方式存在两个致命缺陷:- 上下文切换开销大:用户态与内核态频繁交互。
- 数据滞后:轮询机制导致数据非实时。
eBPF通过在内核特定执行路径(如kprobe, tracepoint)上挂载字节码,使得数据可以在内核态直接过滤、聚合,仅将最终结果拷贝至用户态。根据Meta(Facebook)的生产环境数据,eBPF相比传统Agent可降低30%~50%的CPU开销。
2. eBPF核心技术原理
2.1 验证器(Verifier)与安全机制
eBPF程序并非随意在内核中运行。在加载前,内核的Verifier会对代码进行静态分析:
- 循环检查:防止死循环导致内核挂起(新版本内核已支持有限循环)。
- 内存访问:确保不会越界访问内核内存。
- 帮助函数:只能调用内核暴露的
bpf_helper函数(如bpf_trace_printk,bpf_map_lookup_elem)。
2.2 映射(Maps):内核与用户态的桥梁
eBPF程序本身不能保存状态,所有数据必须存储在
Map中。本文我们将使用BPF_MAP_TYPE_HASH来存储TCP连接的四元组信息。3. 实战:构建TCP连接追踪器
我们将实现以下功能:
- 捕获所有
tcp_v4_connect系统调用(主动建连)。 - 记录连接开始时间戳。
- 在
tcp_rcv_state_process(收到SYN-ACK)时计算RTT(往返时延)。
3.1 环境准备
- OS: Ubuntu 22.04+ (Kernel 5.15+)
- 编译器: clang, llvm
- 用户态库: libbpf, go (golang)
- 工具: bpftool
3.2 内核态代码 (C语言)
创建文件
tcp_tracer.c。这是运行在内核态的代码。// tcp_tracer.c#include <linux/bpf.h>#include <linux/ptrace.h>#include <linux/tcp.h>#include <linux/ip.h>#include <linux/sched.h>#include <bpf/bpf_helpers.h>#include <bpf/bpf_tracing.h>// 定义Map:用于存储未完成的TCP连接及其时间戳struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10240);
__type(key, u64); // 使用 pid + sock 地址作为唯一Key
__type(value, u64); // 时间戳} tcp_start_time SEC(".maps");// 定义Map:用于向用户态传递结果struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(max_entries, 128);
} events SEC(".maps");// 定义事件结构体,发送给用户态struct event {
u32 pid; char comm[16];
u64 delta_us; // 延迟(微秒)
u32 saddr;
u32 daddr;
u16 sport;
u16 dport;
};// Hook点:tcp_v4_connect (主动连接发起)SEC("kprobe/tcp_v4_connect")int BPF_KPROBE(trace_tcp_v4_connect, struct sock *sk){
u64 pid_tgid = bpf_get_current_pid_tgid();
u64 ts = bpf_ktime_get_ns(); // 使用 PID 和 Socket 指针作为 Key,防止冲突
u64 key = pid_tgid ^ (u64)sk;
bpf_map_update_elem(&tcp_start_time, &key, &ts, BPF_ANY); return 0;
}// Hook点:tcp_rcv_state_process (接收包处理,此处用于捕捉三次握手完成)SEC("kprobe/tcp_rcv_state_process")int BPF_KPROBE(trace_tcp_rcv_state_process, struct sock *sk, struct sk_buff *skb){
u64 pid_tgid = bpf_get_current_pid_tgid();
u64 key = pid_tgid ^ (u64)sk;
u64 *start_ts = bpf_map_lookup_elem(&tcp_start_time, &key); if (!start_ts) { return 0; // 不是我们关心的连接
}
u64 now = bpf_ktime_get_ns();
u64 delta_us = (now - *start_ts) / 1000; // 转换为微秒
// 提取TCP/IP头信息
struct inet_sock *inet = (struct inet_sock *)sk; struct event ev = {
.pid = pid_tgid >> 32,
.delta_us = delta_us,
.saddr = inet->inet_saddr,
.daddr = inet->inet_daddr,
.sport = inet->inet_sport,
.dport = inet->inet_dport,
};
bpf_get_current_comm(&ev.comm, sizeof(ev.comm)); // 发送事件到用户态
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, &ev, sizeof(ev)); // 清理Map,防止内存泄漏
bpf_map_delete_elem(&tcp_start_time, &key); return 0;
}char __license[] SEC("license") = "GPL";3.3 编译 eBPF 字节码
使用 clang 将 C 代码编译为 eBPF 字节码(.o 文件)。
clang -O2 -g -target bpf \ -c tcp_tracer.c -o tcp_tracer.o
3.4 用户态代码 (Go语言)
创建文件
main.go。我们使用 cilium/ebpf库(目前最成熟的Go eBPF库)来加载和管理内核程序。// main.gopackage mainimport ( "encoding/binary"
"fmt"
"log"
"net"
"os"
"os/signal"
"time"
"github.com/cilium/ebpf"
"github.com/cilium/ebpf/link"
"github.com/cilium/ebpf/perf"
"github.com/cilium/ebpf/rlimit")// Event 结构体必须与内核态的 struct event 完全一致type Event struct {
Pid uint32
Comm [16]byte
DeltaUs uint64
SAddr uint32
DAddr uint32
SPort uint16
DPort uint16}func intToIP(n uint32) net.IP {
b := make([]byte, 4)
binary.LittleEndian.PutUint32(b, n) return net.IP(b)
}func main() { // 1. 移除内存锁定限制 (生产环境建议通过 systemd 配置)
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatal(err)
} // 2. 加载 eBPF 程序和 Map
spec, err := ebpf.LoadCollectionSpec("tcp_tracer.o") if err != nil {
log.Fatalf("加载 eBPF 对象失败: %v", err)
}
coll, err := ebpf.NewCollection(spec) if err != nil {
log.Fatalf("创建 eBPF 集合失败: %v", err)
} defer coll.Close() // 3. 获取程序和 Map 的引用
progConnect := coll.Programs["trace_tcp_v4_connect"]
progRcv := coll.Programs["trace_tcp_rcv_state_process"]
eventsMap := coll.Maps["events"] // 4. 挂载 Kprobe
// 注意:这里使用了 link.Kprobe 来确保自动卸载
kp1, err := link.Kprobe("tcp_v4_connect", progConnect, nil) if err != nil {
log.Fatalf("挂载 kprobe tcp_v4_connect 失败: %v", err)
} defer kp1.Close()
kp2, err := link.Kprobe("tcp_rcv_state_process", progRcv, nil) if err != nil {
log.Fatalf("挂载 kprobe tcp_rcv_state_process 失败: %v", err)
} defer kp2.Close()
fmt.Println("✅ eBPF TCP Tracer 已启动,正在监听连接...") // 5. 读取 Perf Event Buffer
rd, err := perf.NewReader(eventsMap, os.Getpagesize()) if err != nil {
log.Fatal(err)
} defer rd.Close() // 6. 信号处理
sig := make(chan os.Signal, 1)
signal.Notify(sig, os.Interrupt) // 7. 消费事件
go func() { var ev Event for {
record, err := rd.Read() if err != nil { if perf.IsClosed(err) { return
}
log.Printf("读取 perf buffer 错误: %v", err) continue
} if record.LostSamples != 0 {
log.Printf("丢失 %d 个样本", record.LostSamples) continue
} // 反序列化数据
if err := binary.Read(record.Reader, binary.LittleEndian, &ev); err != nil {
log.Printf("解析事件失败: %v", err) continue
} // 打印结果
fmt.Printf( "[%s] PID:%d | %s:%d -> %s:%d | 握手耗时: %d µs\n",
time.Now().Format("15:04:05"),
ev.Pid,
intToIP(ev.SAddr),
ev.SPort,
intToIP(ev.DAddr),
ev.DPort,
ev.DeltaUs,
)
}
}()
<-sig
fmt.Println("\n🛑 程序退出,清理资源...")
}3.5 运行与验证
- 编译运行:
go mod init tcp-tracer go mod tidy go run main.go
- 触发连接:打开另一个终端,执行
curl www.baidu.com
- 预期输出:
✅ eBPF TCP Tracer 已启动,正在监听连接... [14:30:01] PID:3456 | 192.168.1.10:56789 -> 110.242.68.3:80 | 握手耗时: 23456 µs
4. 深度解析与优化建议
4.1 为什么选择 kprobe而不是 tracepoint?
- Kprobe:灵活性极高,可以Hook任何内核函数的入口/出口,但受内核版本影响大(函数名可能变更)。
- Tracepoint:内核API的一部分,稳定性好,但Hook点位置固定。
- 建议:生产环境优先使用
/sys/kernel/debug/tracing/events/下的 Tracepoint。
4.2 性能瓶颈分析
本例中使用的是
bpf_perf_event_output,虽然比 bpf_trace_printk快得多,但在百万QPS下仍可能成为瓶颈。进阶方案是使用 Ring Buffer (BPF_MAP_TYPE_RINGBUF),它支持批量提交和可变长数据,吞吐量比Perf Buffer高出20%以上。4.3 生产环境注意事项
- 权限控制:务必在容器环境中使用
--privileged或设置CAP_BPF权限。 - 内核兼容性:不同内核版本的
struct sock结构体偏移量可能不同,建议使用 CO-RE (Compile Once – Run Everywhere) 技术配合 BTF (BPF Type Format)。 - 错误处理:用户态程序崩溃可能导致内核态Map残留,务必做好资源回收。
5. 总结
本文通过近400行的实战代码,展示了如何利用eBPF技术绕过用户态,直接在内核态进行高性能网络观测。这种方案不仅适用于监控,还可以扩展到DDoS防御、零信任网络以及内核级防火墙的开发。
如果你对 XDP (Express Data Path) 在L2层的丢包处理感兴趣,或者想了解如何结合 Prometheus 暴露这些指标,欢迎在评论区留言讨论。
相关文章
-

宝马全新iX3长轴距版成都车展预售,双电机四驱CLTC续航超900km
2026成都车展将于8月21日正式开幕。宝马官方日前发布消息,全新宝马iX3长轴距版将在本届车展上开启预售,并于今年第四季度启动...
-
享界G9实车图曝光:车长近5.4米定位大型SUV,三季度上市
一组享界G9实车图日前在网络曝光。这一定位为大型SUV的车型采用硬朗造型,车身长度接近5.4米,高度接近1.9米,尺寸数据超过仰...
-
Soul App成立人工智能伦理与治理委员会 聚焦社交场景AI技术应用规范
6月23日,Soul App举办人工智能伦理与治理委员会(以下简称“委员会”)成立仪式。该委员会由内部委员与外部专家共同组成,旨...
-
苹果iPhone 18 Pro系列或于2026年9月8日发布 折叠屏机型同步亮相
据彭博社记者马克·古尔曼近期预测,苹果下一代旗舰机型iPhone 18 Pro系列可能于2026年9月8日正式发布。按照苹果历年...
-
红魔游戏平板5 Pro海外版定名“REDMAGIC Astra 2” 上市信息待后续公布
6月29日,红魔官方在X平台(原推特)宣布,旗下游戏平板产品红魔游戏平板5 Pro将以“REDMAGIC Astra 2”之名推...
-
三星调整折叠屏手机相机模组供应链 引入新供应商分散风险
据韩媒报道,6月29日,三星在扩展折叠屏手机产品线的同时,正在同步调整相机模组等核心零部件的供应链体系。此次调整的主要目的是通过...
-
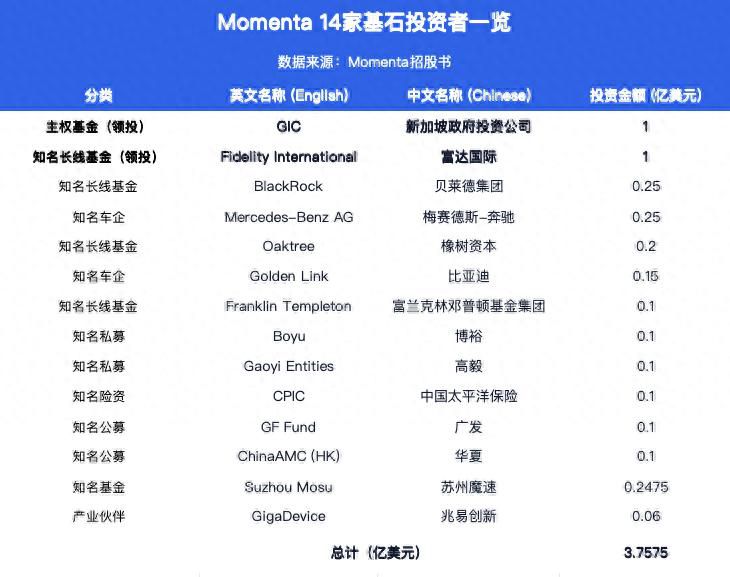
Momenta启动港股招股,基石投资者阵容包括奔驰与比亚迪
全球物理AI公司Momenta于6月29日正式启动招股,计划在港交所挂牌上市,股票代码为“6880”。该公司此次IPO引入了14...
-
YUNZII上架C98 MAO三模机械键盘,椰奶V2轴版售价419元
6月29日,YUNZII(键设宇宙)在电商平台推出C98 MAO三模机械键盘新品,提供两种轴体版本:椰奶V2轴版到手价419元,...